こんにちは、エンジニアのトミーです。
ギークフィードアドベントカレンダー 2024、19日目の記事です!
RDSの再起動にはダウンタイムがつきものです。
ダウンタイムは単なる技術的な問題にとどまらず、その調査や対策に時間とリソースが発生し業務全体への影響も考えられます。
今回のブログでは、意図しないRDSの再起動が発生した事例を通じて、その原因と調査手順を備忘録的に書き残していきます。
結論
今回の調査により、RDSが稼働していたホストコンピューターの基盤において、一時的な問題が発生したため、RDSインスタンスが意図せず停止したことが明らかになりました。
以下は「なぜ再起動が発生したのか」という視点での具体的な調査内容と経緯です。今後のトラブルシューティングやシステム運用において参考になることを願っています。
再起動発生から発覚まで
RDSイベントサブスクリプションからイベント発生のメールが届き再起動が発覚しました。
以下のような内容で届きます。
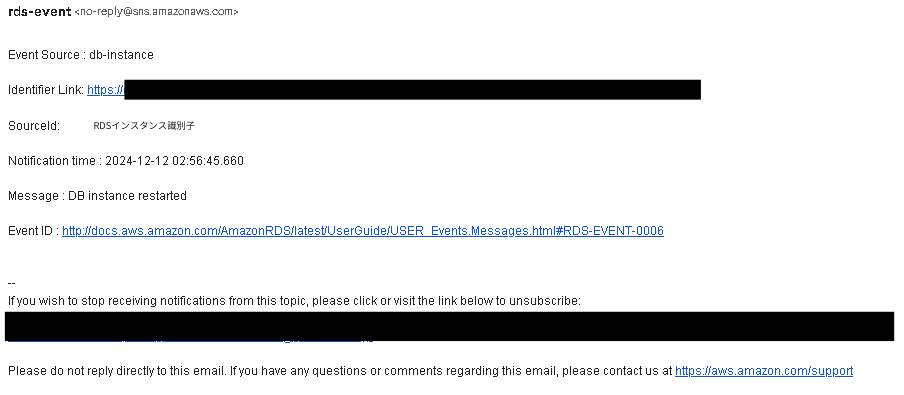
写真び下部に記載のある「Event ID」のURLを叩くと、具体的にどのような理由で再起動が行われたのかが確認できます。
URL末尾のEVENT-006が発生事象の具体的な内容となっているので、確認しに行きます。

今回は「DBインスタンスが再起動しました。」が通知理由に当たります。
このほかにもストレージ変更を通知したり、フェイルオーバーやバックアップイベントの失敗をお知らせしてくれる便利ツールです。是非設定すべきです。
人為的に再起動が行われていても同じ内容のメールが届くので、あくまでざっくりとした切り分けが出来る「RDSイベント」の通知ツールとして使うべきですね。
再起動の発生が発覚したので、具体的に内容を確認しましょう。
原因調査のために行った作業一覧
切り分けのため、以下の手順で確認していきます。
- 1.顧客へのエスカレートと手動での再起動実行を行ったかの確認(CloudTrail)
- 2.AWS Health Dashboardでの障害情報確認
- 3.対象 RDS のメンテナンスタブ, 最近のイベント, error ログ
- 4.Performance Insights
- 5.AWSサポートへの連絡
切り分けのため、考えられる再起動理由を前もって切り出しておきます。
- 1.AWSの障害
- 2.スペック不足
- 3.意図的に実行
CloudTrail
CloudTrailを利用して、意図的に手動で再起動が実行されたかどうかを確認することが出来ます。
以下の条件で検索します。
ルックアップ属性:イベントソース, ソース名:rds.amazonaws.com
※画像はブログ用に作成したインスタンスです。
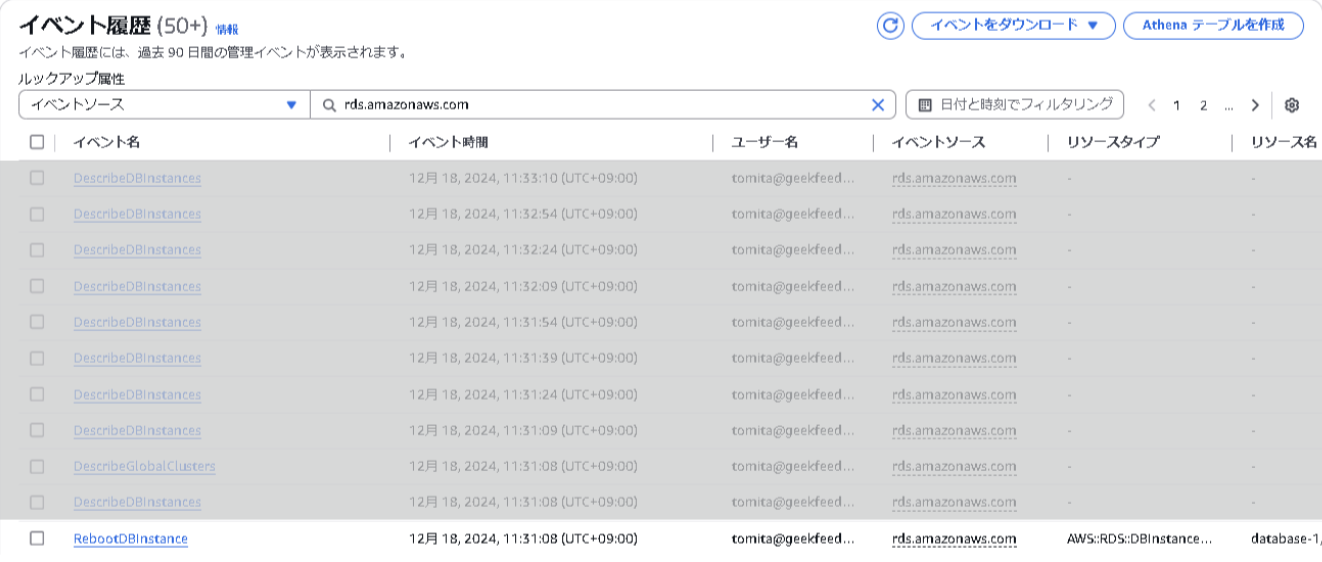
RebootDBInstanceが見つかれば、意図的な再起動が行われたことがわかります。
もし再起動が手動で行われていないなら、次のステップに進み、AWS側の問題かRDSのスペックによる問題なのかを確認しに行きます。
AWS Health Dashboardでの障害情報確認
AWSから障害情報が出ているときはAWS Health Dashboardから確認できます。
Dashboard内の、サービス履歴から以下の条件で確認してみます。
サービス: RDS, 日付: 2024/12/12, ロケーション:アジア
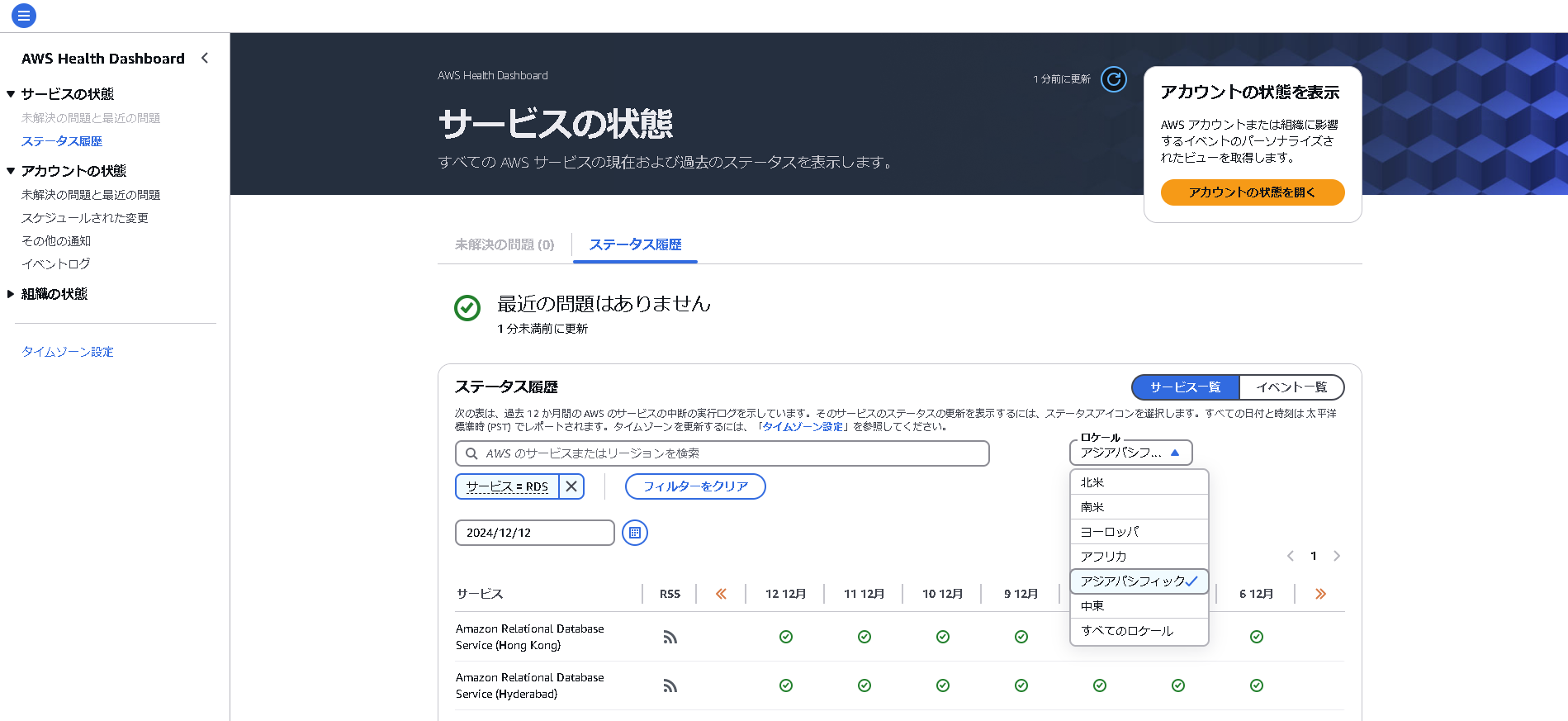
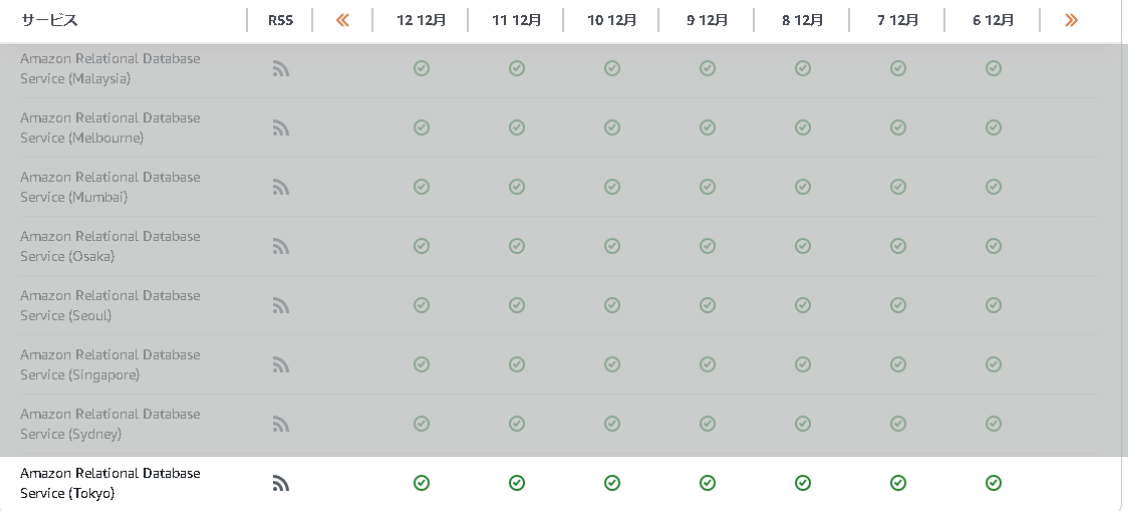
Tokyoリージョンがでてくるので確認してみますが…障害は発生していないようでした。
余談ですが、私は「障害か…?」と疑いが出たら必ずAWS障害情報の以下のX(旧Twitter)を確認するようにしています。
AWS障害情報(国内リージョン関連のみ)
是非確認してみてください。
具体的に何が起きたのか調査が必要なのでRDSの設定・ログ確認を行います。
RDSログ調査
RDSには「RDSイベントログ」という直近起きたイベントを表示してくれる機能があるので確認していきます。
コンソールから確認する場合は、対象のインスタンスを表示し「ログとイベント」から確認することが出来ます。
※表示できるのは24時間以内に起きたイベントのみ
本来であればコンソール画面を共有したかったのですが、24時間を過ぎていたのでCLIコマンドから取得した過去のログを表示しておきます。
以下は過去一週間分のイベントログを出力するコマンドです。「database-name」の部分にRDSインスタンス識別子を記入してください。
|
1 |
aws rds describe-events --duration 10080 --source-identifier database-name --source-type db-instance |
以下は実際に再起動が発生した時刻のログになります。
※UTC表記
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
"SourceIdentifier": "DatabaseName", "SourceType": "db-instance", "Message": "Recovery of the DB instance has started. Recovery time will vary with the amount of data to be recovered.", "EventCategories": [ "recovery" ], "Date": "2024-12-12T02:49:48.430000+00:00", "SourceArn": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" }, { "SourceIdentifier": "DatabaseName", "SourceType": "db-instance", "Message": "Recovery of the DB instance is complete.", "EventCategories": [ "recovery" ], "Date": "2024-12-12T02:56:09.918000+00:00", "SourceArn": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" }, { "SourceIdentifier": "DatabaseName", "SourceType": "db-instance", "Message": "DB instance restarted", "EventCategories": [ "availability" ], "Date": "2024-12-12T02:56:45.660000+00:00", "SourceArn": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" }, |
ログからRecoveryが自動的に実行されていることが確認できました。
これよりも前のログは前日の6時台(8時間前)だったので、急にRecovaryが走っていることになります。
このログ内容を検索したのですが、日本語で引っかかるサイトはなく珍しい事象なんだな…と思っていました。
最後にPerformance Insightsを確認して再起動発生時刻に異常な挙動やがないか確認します。
ここでも問題は見つからなかったので、立ち行かなくなりAWSサポートに連絡を行いました。
まとめ
最終的に、AWSサポートから「RDS基盤が稼働していたホストコンピューターで一時的な問題が発生し、意図しない再起動が発生した」との回答を受け、AWSで障害が起きていたとして問題が解決しました。
シャットダウンから再起動までのダウンタイムは5分程度で、RDSイベントサブスクリプション通知は再起動が完全に完了してから受け取りになりました。
本環境では採用していないのですがこういった場合に備えてマルチAZでの運用やダウンタイムを最小化することが非常に大切であると実感しました。
また、今回のような障害については、再起動が発生してもAWSから障害情報が提供されないことが分かりました。
RDSイベントサブスクリプションで通知を受け取れていたため迅速な対応を行うことが出来ましたが、今後も監視体制については強化していく必要があるなと認識させられました。
このブログが、同様の問題に直面した際の参考となり、皆様のシステム運用に役立つことを願っています。
- 【Amazon RDS】意図せず突発的な再起動が起こった原因 - 2024-12-19
- 【AWS CDK】RDS L2で指定できないエンジンバージョンを使用する方法を実装しました。 - 2023-12-21
- AWS ベストプラクティスに沿った作業を確実に! 知識の宝庫 AWS 規範的ガイダンスの使い方 - 2023-12-09
【採用情報】一緒に働く仲間を募集しています