こんにちは。
昨年からアルバイトとしてギークフィードでエンジニアをしている鈴木です。PHPやHTML+JSを使ってWEBシステム開発などをしています。
弊社ではWEBシステム開発にAWSを利用してから数年が経過し、複数のアカウント・サービスに渡ってAWSリソースが乱立しました。
その結果、誰がどのリソースを管理しているのか把握しにくくなっているという問題に直面しました。
そこで、社内で利用しているAWSリソースをGoogleスプレッドシート上で自動的にリストアップするLambda関数を作成し、管理者が編集・記録できるようにしました。
Lambda関数はPythonで書き、boto3とgspreadの2つのライブラリを主に利用しました。
この記事では主に、
- STS AsuumeRoleを利用した複数AWSアカウントへのアクセス
- Lambdaでgspreadを使用する際の注意点
について紹介します。
boto3やgspreadの基本的な利用方法については割愛します。
僕自身のPython歴に関しては、研究室で実験データの処理に使っている(100行未満)程度の初心者なので、Python・Lambdaの勉強に丁度良い内容だと思います。
目次
作成したプログラムについて
先程紹介した通り、AWSリソースの乱立によって管理者の把握が困難となってしまい、一度手作業でリソースをスプレッドシートにリストアップしました。
マネジメントコンソールではサービスごとにインスタンスやリソースの一覧表示は可能なのですが、複数サービス・複数アカウントのリソースをまとめて表示する方法はなく、手作業でリストアップしていくのは相当の労力が必要とされます。
そこで、Lambdaとgspreadを利用しリソースをまとめてリストアップします。
目標イメージ
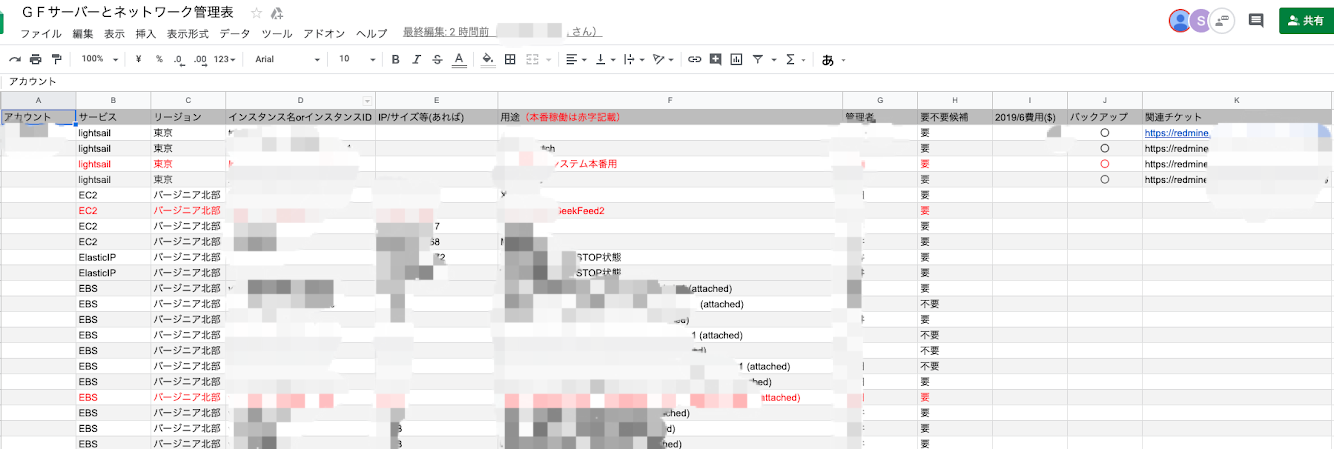
こちらは、手作業でまとめた際のスプレッドシートです。シートの左側にリソースの基本的な情報をまとめ、右側に管理者や使用用途などを記録し管理していきます。
毎日自動で更新が行われ、リソースが増えたら下に追加していきます。
管理者や使用用途などの情報は手動で追記していくため、更新の際は、左側の情報のみを更新します。
完成したスプレッドシート
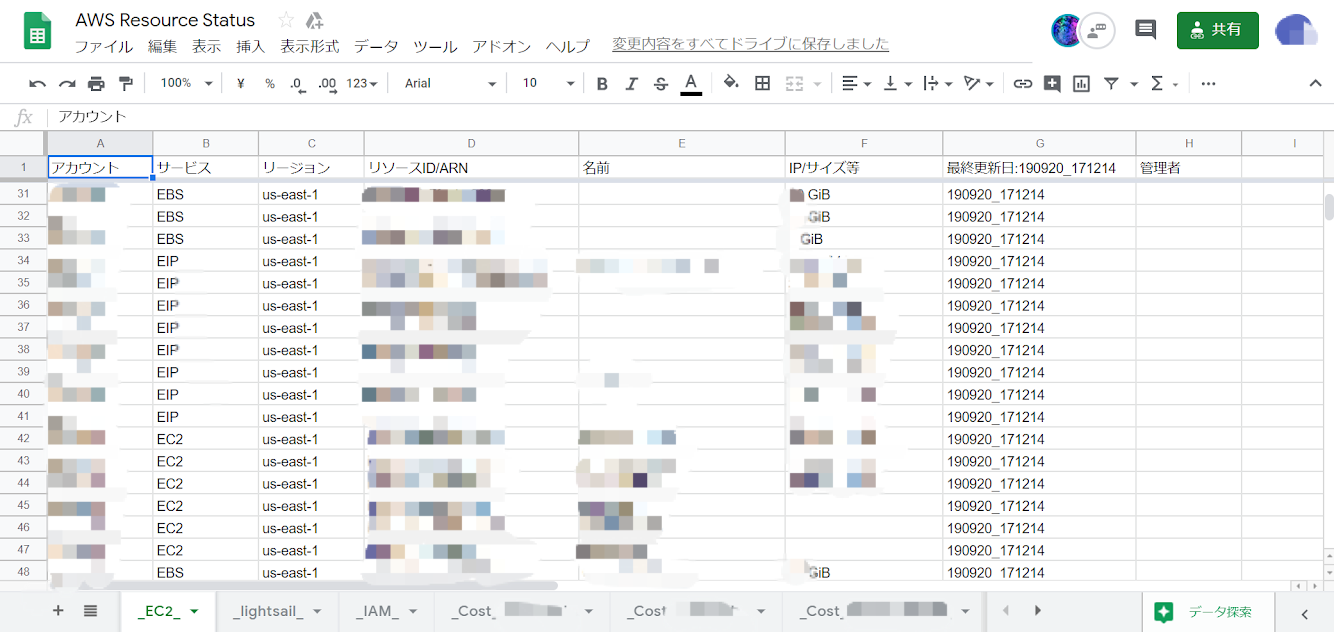
このように、複数アカウントのEC2・Lightsail・IAMなどの情報を一つのGoogleスプレッドシート上にまとめてリストアップすることができました。
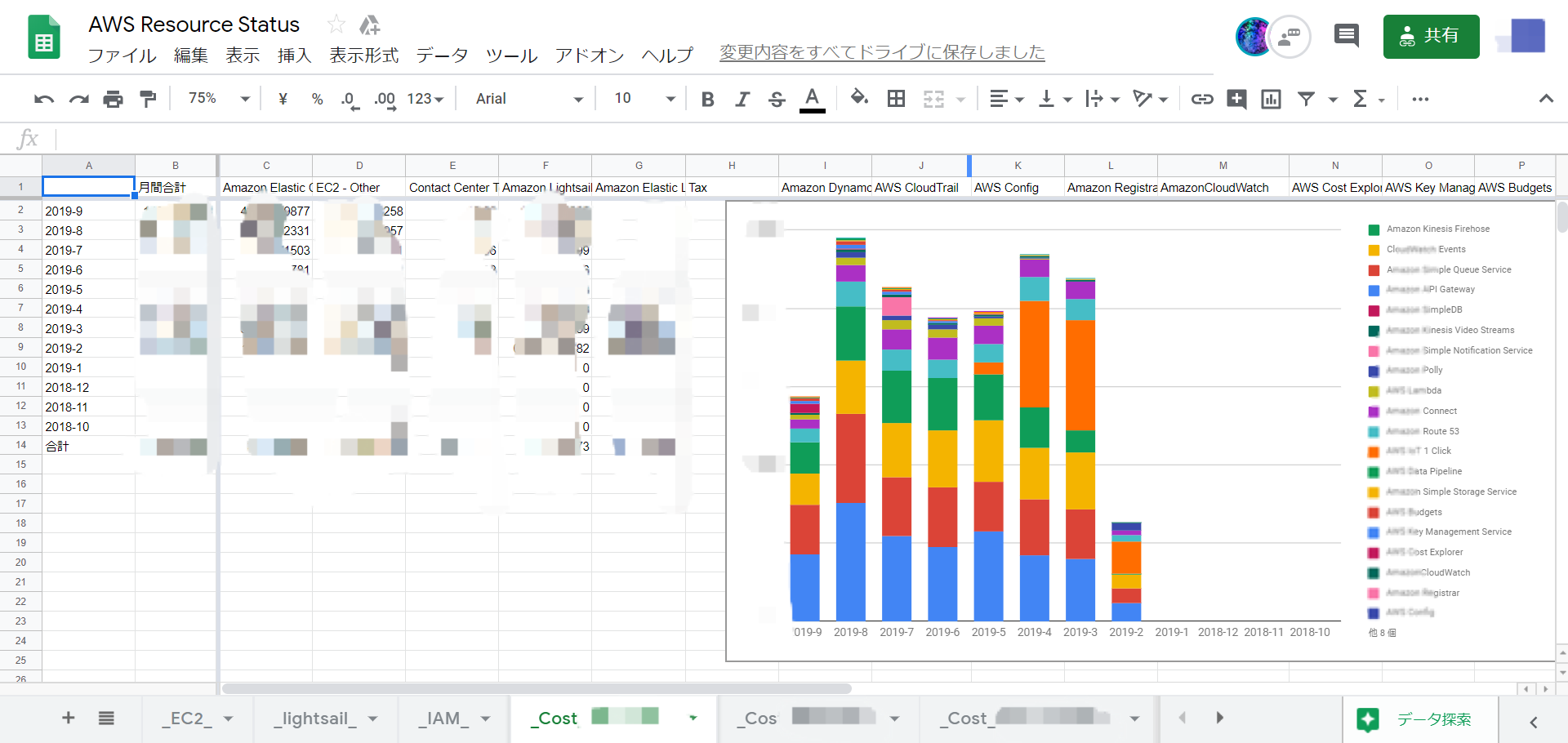
また、コストに関しても3アカウントの情報をシートごとにまとめるようにしました。どのアカウントがどのくらい稼働しどのくらい費用がかかっているか簡単に確認することができます。
今後はこのスプレッドシートを活用して、リソースの管理をおこなっていきます。
プログラムの概略
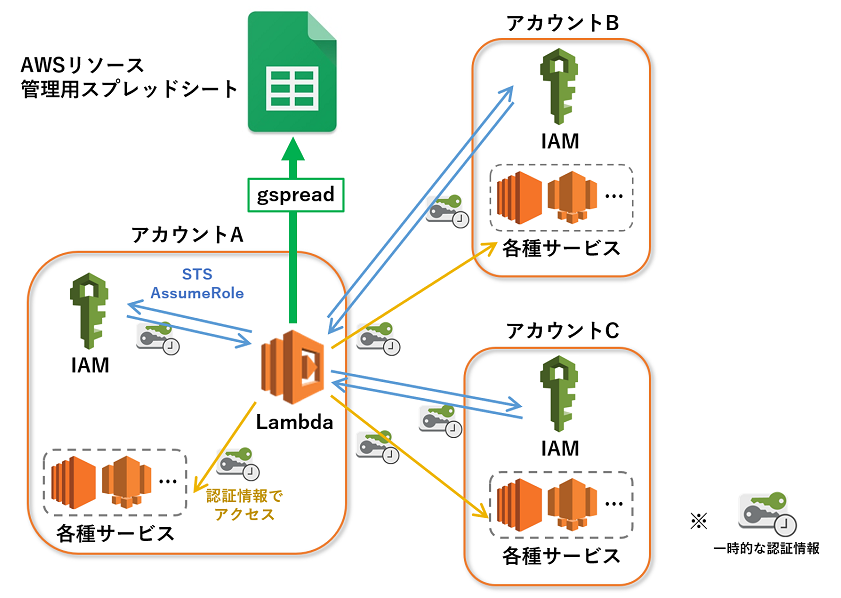
現状弊社では3つのAWSアカウントを運用しているのですが、将来的にアカウントは増・減・統合の可能性があるため、Lambda関数はアカウントごとに分散させず、一つのLambda関数で完結させることにしました。
その結果、上の図のように、アカウントAのLambda関数からSTS AssumeRoleを用いて3アカウント分のリソース情報を取得し、取得した情報をもとにスプレッドシートを更新するようにしました。
ソースコード
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 |
import json import boto3 import gspread import datetime from oauth2client.service_account import ServiceAccountCredentials def lambda_handler(event, context): # eventパラメータからアカウントごとのARNを取得 accounts = event['body']['accounts'] # データを取得しdata_listとcost_listに追加していく data_list = [] cost_list = [] sts_client = boto3.client('sts',endpoint_url="https://sts.ap-northeast-1.amazonaws.com",use_ssl=True) # アカウントごとにデータを取得していく for account in accounts: # STS経由でcredentialを取得 account_name = account['name'] account_arn = account['arn'] role_session_name = f"{account_name}-sts" credentials = sts_client.assume_role(RoleArn = account_arn, RoleSessionName = role_session_name)["Credentials"] # get関数を呼びdata_listに追加していく data_list.extend(get_ec2_instances(credentials, "us-east-1", account_name)) data_list.extend(get_ebs_volumes(credentials, "us-east-1", account_name)) data_list.extend(get_eip_instances(credentials, "us-east-1", account_name)) data_list.extend(get_lightsail_instances(credentials, "ap-northeast-1", account_name)) data_list.extend(get_iam_users(credentials, account_name)) # get関数を呼びcost_listに追加していく cost_list.append({'sheet':f'_Cost_{account_name}_','cost':get_cost_and_usage(credentials, account_name)}) # gspreadのauthorizeを得る g_scope = ['https://spreadsheets.google.com/feeds', 'https://www.googleapis.com/auth/drive'] g_credentials = ServiceAccountCredentials.from_json_keyfile_name('xxxxxxxxxxxxxx.json',g_scope) g_doc = gspread.authorize(g_credentials).open_by_key('xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx') # シートごとに更新の関数を呼ぶ(処理数を節約するためにサービス名でフィルターしたdata_listを渡す) update_ec2_sheet(list(filter(lambda x: x['serviceName'] in ['EC2', 'EBS', 'EIP', 'EC2Snapshots'],data_list)), g_doc.worksheet('_EC2_')) update_lightsail_sheet(list(filter(lambda x: x['serviceName'] in ['lightsail', 'lightsailSnapshots'],data_list)), g_doc.worksheet('_lightsail_')) update_iam_sheet(list(filter(lambda x: x['serviceName'] in ['IAM'],data_list)), g_doc.worksheet('_IAM_')) # Costシートはアカウントごとに1シートあるので、アカウントごとに更新する for cost in cost_list: update_cost_sheet(cost['cost'], g_doc.worksheet(cost['sheet'])) def get_ec2_instances(credentials, region_name, account_name): # 引数で渡された認証を用いてboto3クライアントを取得する ec2 = boto3.client('ec2', aws_access_key_id = credentials['AccessKeyId'], aws_secret_access_key = credentials['SecretAccessKey'], aws_session_token=credentials['SessionToken'], region_name = region_name) # 基本的にdescribeやget関数を用いてリソース情報を取得する reservations = ec2.describe_instances()['Reservations'] add_info = {'regionName':region_name,'serviceName':'EC2','accountName':account_name,'idKeyName':'InstanceId'} results = [{**y,**add_info} for x in reservations for y in x['Instances']] # インスタンスに名前が付けられていれば情報を追加する for i in range(len(results)): if 'Tags' in results[i]: name_values = [x['Value'] for x in results[i]['Tags'] if x['Key'] == 'Name'] results[i]['resourceName'] = name_values[0] if len(name_values) else '' else: results[i]['resourceName'] = '' return results """ ~get関数省略(基本的にget_ec2_instancesと同じ要領)~ """ def update_ec2_sheet(data_list, worksheet): # 7行目までをこのプログラムで編集する edit_row_num = 7 # 最終更新日を更新 now = datetime.datetime.now().strftime('%y%m%d_%H%M%S') worksheet.update_cell(1,7,f"最終更新日:{now}") # ID判定用のリストと更新範囲を取得 resource_ids = worksheet.col_values(4) update_cells = worksheet.range(1,1,len(resource_ids),edit_row_num) # 更新内容をサービスごとに整理する append_rows = [] for data in data_list: resource_id = data[data['idKeyName']] if data['serviceName'] == 'EC2': append_row = [data['accountName'], data['serviceName'], data['regionName'], resource_id, data['resourceName'], data['PublicIpAddress'] if 'PublicIpAddress' in data else '', now] elif data['serviceName'] == 'EBS': append_row = [data['accountName'], data['serviceName'], data['regionName'], resource_id, data['resourceName'], f"{data['Size']} GiB", now] elif data['serviceName'] == 'EIP': append_row = [data['accountName'], data['serviceName'], data['regionName'], resource_id, data['resourceName'], data['PublicIp'], now] elif data['serviceName'] == 'EC2Snapshots': append_row = [data['accountName'], data['serviceName'], data['regionName'], resource_id, data['resourceName'], '', now] else: continue if resource_id in resource_ids: # すでにIDが存在すれば更新 update_row = resource_ids.index(resource_id) for i in range(len(append_row)): update_cells[update_row*edit_row_num + i].value = append_row[i] else: # IDが存在しなければappend_rowsに追加しておく append_rows.append(append_row) # update_cellsの範囲を更新 worksheet.update_cells(update_cells) # append_rowsに新規項目があればまとめて追加 if append_rows: update_cells = worksheet.range(len(resource_ids)+1,1,len(resource_ids)+len(append_rows),edit_row_num) for i in range(len(append_rows)): for j in range(len(append_rows[i])): update_cells[i*edit_row_num + j].value = append_rows[i][j] worksheet.update_cells(update_cells) """ ~update関数省略(基本的にupdate_ec2_sheetと同じ要領)~ """ |
get関数とupdate関数が大部分を占めるため、一部省略しています。
ハンドラー関数では主に
- AssumeRoleを用いてアカウントごとにリソース情報を取得
- スプレッドシートへの認証処理
- シートごとに更新
という処理が行われます。
リソース情報の取得
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# eventパラメータからアカウントごとのARNを取得 accounts = event['body']['accounts'] # データを取得しdata_listとcost_listに追加していく data_list = [] cost_list = [] sts_client = boto3.client('sts',endpoint_url="https://sts.ap-northeast-1.amazonaws.com",use_ssl=True) # アカウントごとにデータを取得していく for account in accounts: # STS経由でcredentialを取得 account_name = account['name'] account_arn = account['arn'] role_session_name = f"{account_name}-sts" credentials = sts_client.assume_role(RoleArn = account_arn, RoleSessionName = role_session_name)["Credentials"] # get関数を呼びdata_listに追加していく data_list.extend(get_ec2_instances(credentials, "us-east-1", account_name)) data_list.extend(get_ebs_volumes(credentials, "us-east-1", account_name)) data_list.extend(get_eip_instances(credentials, "us-east-1", account_name)) data_list.extend(get_lightsail_instances(credentials, "ap-northeast-1", account_name)) data_list.extend(get_iam_users(credentials, account_name)) # get関数を呼びcost_listに追加していく cost_list.append({'sheet':f'_Cost_{account_name}_','cost':get_cost_and_usage(credentials, account_name)}) |
アカウントの名前とRoleArnはeventパラメータで渡しています。配列data_listとcost_listに取得したデータを追加していきます。
boto3関数の返り値の構造はサービスによって異なるので、サービスごとにget関数を定義しています。
assume_role()関数によって一時認証情報(credeentials)を発行し、データの取得を行います。むやみにassumeRoleの発行を繰り返さないように、アカウントごとにまとめてget関数を呼び出しています。
スプレッドシートへの認証処理
|
1 2 3 4 |
# gspreadのauthorizeを得る g_scope = ['https://spreadsheets.google.com/feeds', 'https://www.googleapis.com/auth/drive'] g_credentials = ServiceAccountCredentials.from_json_keyfile_name('xxxxxxxxxxxxxx.json',g_scope) g_doc = gspread.authorize(g_credentials).open_by_key('xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx') |
gspreadの公式ドキュメントを参考に認証用jsonキーファイルを取得します。
取得したjsonファイルはapp.pyと同じレイヤーにアップロードしました。
from_json_keyfile_name()よりgspreadの認証情報を発行し、スプレッドシートを展開します。
シートごとに更新
|
1 2 3 4 5 6 7 |
# シートごとに更新の関数を呼ぶ(処理数を節約するためにサービス名でフィルターしたdata_listを渡す) update_ec2_sheet(list(filter(lambda x: x['serviceName'] in ['EC2', 'EBS', 'EIP', 'EC2Snapshots'],data_list)), g_doc.worksheet('_EC2_')) update_lightsail_sheet(list(filter(lambda x: x['serviceName'] in ['lightsail', 'lightsailSnapshots'],data_list)), g_doc.worksheet('_lightsail_')) update_iam_sheet(list(filter(lambda x: x['serviceName'] in ['IAM'],data_list)), g_doc.worksheet('_IAM_')) # Costシートはアカウントごとに1シートあるので、アカウントごとに更新する for cost in cost_list: update_cost_sheet(cost['cost'], g_doc.worksheet(cost['sheet'])) |
今回、シートをサービスごとにわけてリソースをリストアップしたため、更新用のupdate関数はシートごとに定義しました。
update関数については、リソース情報が収集されたdata_list配列と、worksheet()によって得たシートを渡しています。
gspreadの操作方法については後述します。
STS AsuumeRoleを利用した複数AWSアカウントへのアクセス
STS AssumeRoleを用いて特定のアカウントへのアクセスを許可しておけば、アクセスキーとシークレットアクセスキーを用いずにセキュアに外部アカウントへのアクセスが可能となります。
AssumeRoleを用いて一時認証情報を発行するには以下のようにアカウント双方でロールを作成する必要があります。
アカウントA側のロール
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "logs:*" ], "Resource": "arn:aws:logs:*:*:*" }, { "Effect": "Allow", "Action": [ "lambda:InvokeFunction", "lambda:InvokeAsync", "sts:AssumeRole" ], "Resource": [ "*" ] } ] } |
このように、アカウントA側ではAssumeRoleへのフルアクセスを与える必要があります。
また、アカウントAでLambdaが実行されるため、LambdaとCloudWatchへのフルアクセスも与えています。
アカウントA・アカウントB・アカウントC側のロール
アクセスされるアカウント側には「クロスアカウントアクセスのロール」を与える必要があります。
今回のプログラムでは、全てのリソースへのアクセスにAssumeRoleを用いているため、自アカウント(アカウントA)にもクロスアカウントアクセスのロールを与えています。
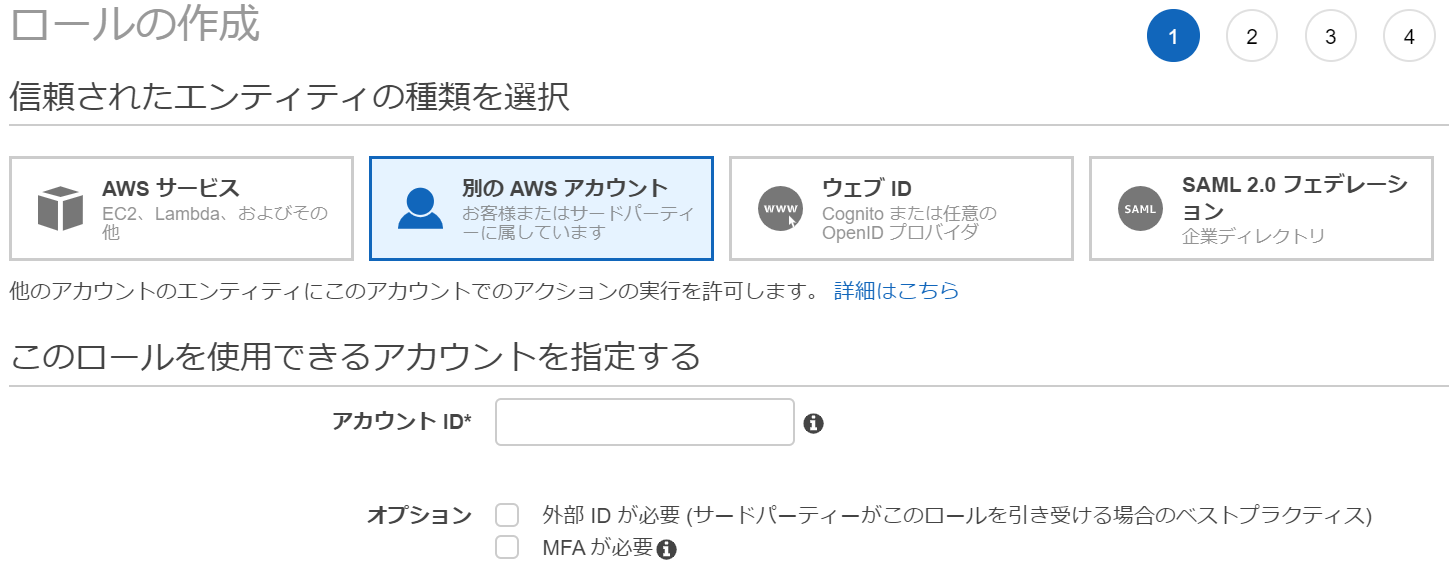
クロスアカウントアクセスのロールは、ロール作成時にエンティティの種類を「別のAWSアカウント」にすることで作成できます。アカウントIDにはアカウントAのIDを入力します。

今回、このロールにはEC2・Lightsail・IAM・Costへのリードオンリーアクセスを与えました。このように、双方のアカウントに適切なロールを与えることで、assume_role()関数より一時認証情報を発行することができます。
Lambdaでgspreadを使用する際の注意点
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
def update_ec2_sheet(data_list, worksheet): # 7行目までをこのプログラムで編集する edit_row_num = 7 # 最終更新日を更新 now = datetime.datetime.now().strftime('%y%m%d_%H%M%S') worksheet.update_cell(1,7,f"最終更新日:{now}") # ID判定用のリストと更新範囲を取得 resource_ids = worksheet.col_values(4) update_cells = worksheet.range(1,1,len(resource_ids),edit_row_num) # 更新内容をサービスごとに整理する append_rows = [] for data in data_list: resource_id = data[data['idKeyName']] if data['serviceName'] == 'EC2': append_row = [data['accountName'], data['serviceName'], data['regionName'], resource_id, data['resourceName'], data['PublicIpAddress'] if 'PublicIpAddress' in data else '', now] elif data['serviceName'] == 'EBS': append_row = [data['accountName'], data['serviceName'], data['regionName'], resource_id, data['resourceName'], f"{data['Size']} GiB", now] elif data['serviceName'] == 'EIP': append_row = [data['accountName'], data['serviceName'], data['regionName'], resource_id, data['resourceName'], data['PublicIp'], now] elif data['serviceName'] == 'EC2Snapshots': append_row = [data['accountName'], data['serviceName'], data['regionName'], resource_id, data['resourceName'], '', now] else: continue if resource_id in resource_ids: # すでにIDが存在すれば更新 update_row = resource_ids.index(resource_id) for i in range(len(append_row)): update_cells[update_row*edit_row_num + i].value = append_row[i] else: # IDが存在しなければappend_rowsに追加しておく append_rows.append(append_row) # update_cellsの範囲を更新 worksheet.update_cells(update_cells) # append_rowsに新規項目があればまとめて追加 if append_rows: update_cells = worksheet.range(len(resource_ids)+1,1,len(resource_ids)+len(append_rows),edit_row_num) for i in range(len(append_rows)): for j in range(len(append_rows[i])): update_cells[i*edit_row_num + j].value = append_rows[i][j] worksheet.update_cells(update_cells) |
EC2シートのupdate関数は上のようになっています。
Lambdaでgspreadを自動運用する際にはいくつか注意する点があります。
基本的な操作の説明
update関数では、スプレッドシートの「リソースID/ARN」の列から既に登録されているID/ARNを取得(10行目)し、更新範囲(11行目で取得)に対し
- 既にID/ARNが存在されていれば情報を更新
- ID/ARNがまだ存在していなければ追加
という風に処理することでスプレッドシートを更新しています。
APIのリクエスト制限
当初は、リソース情報1行分ごとにループしてfind()関数で既存/新規を判定→update()/append()という風なプログラムにしていました。
しかし、find()/update()/append()を多用していたところ
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
{ "error": { "code": 429, "message": "Quota exceeded for quota group 'WriteGroup' and limit 'USER-100s' of service 'sheets.googleapis.com' for consumer 'project_number:xxxxxxxxxxxx'.", "status": "RESOURCE_EXHAUSTED", "details": [ { "@type": "type.googleapis.com/google.rpc.Help", "links": [ { "description": "Google developer console API key", "url": "https://console.developers.google.com/project/xxxxxxxxxxxxx/apiui/credential" } ] } ] } } |
というエラーが発生してしまいました。
“Usage Limits | Sheets API | Google Developers”によると、GoogleスプレッドシートのAPIには
- プロジェクトに対し500リクエスト/100秒の上限
- ユーザーに対し100リクエスト/100秒の上限
という制限があるため、1行分ごとに更新場所の判定(find()など)とデータの更新(update()かappend())をループで処理すると、登録するデータ×2回のリクエストが発生してしまいエラーとなってしまいます。
なので、極力range()とupdate_cells()を使うことで、一括にデータの更新をする必要があります。
プログラムによっては、time.sleep()などを使って100秒間当たりのリクエスト回数を減らすという手もありますが、Lambda関数では時間制限があるためおすすめできません。
終わりに
今回、Lambdaとgspreadを組み合わせることで、AWSリソースの各情報をGoogleスプレッドシートにリストアップすることができました。
運用しているアカウント・リソースが増え、管理者も分散してしまうと、AWSマネジメントコンソール以外の方法でリソースを記録・確認していく必要があると思います。
そのような時、Lambdaを利用すれば比較簡単にリストアップの自動化ができるとわかりました。
- 【React】フロントエンドのテストコードを書いてみよう【Vitest】 - 2024-04-30
- Simple AWS DeepRacer Reward Function Using Waypoints - 2023-12-19
- Restrict S3 Bucket Access from Specified Resource - 2023-12-16
- Expand Amazon EBS Volume on EC2 Instance without Downtime - 2023-09-28
- Monitor OpenSearch Status On EC2 with CloudWatch Alarm - 2023-07-02
【採用情報】一緒に働く仲間を募集しています