こんにちは。唐突ですが、今回はJuliusに触れる機会があったので、Juliusについて書こうと思います!
(例に漏れず初心者向けの内容になっておりますので、ご了承ください。。)
ちなみに今回は、ブラウザから音声アップロード→Juliusで音声認識→結果をブラウザ画面に表示というのをNode.JSを使って実施したので、それに関するあれやこれやを記載していこうと思います。
目次
Juliusとは
正直私はここからでした。検索すれば色々出てくるのですが、公式サイトには以下の様に説明されております。
音声認識システムの開発・研究のためのオープンソースの高性能な汎用大語彙連続音声認識エンジンです. 数万語彙の連続音声認識を一般のPCやスマートフォン上でほぼ実時間で実行できる軽量さとコンパクトさを持っています.(http://julius.osdn.jp/より)
オープンソースの音声認識システムということで、検索すると色んな方が色々試しているのが出てきます。また、商用利用も可、オフラインでも利用可能というところに大きな魅力があります。
認識率については、20,000語彙の読み上げ音声で90%以上と記載があります。ただこのあたりは辞書登録の内容の精度によって変わるっぽいです。
今回はJulius公式のdictation-kitを利用したのですが、認識率としてはうーん。。という感じでした。
(アナウンサーのようなハキハキとした喋り、雑音等ない音源だとある程度認識してくれるかな、というような印象。ここでは記載しませんがGoogle Cloud Speech APIを使って同じことをできるようにしたのですが、同じ音源でもやはりGoogleの方はかなり精度高く認識してました。)
やったこと
今回はJuliusを実装したサーバで直接音声を扱うのではなく、別のPCからブラウザ経由で対象のサーバに音声を送り、そこで認識結果を出してブラウザ上に表示させるというやり方をしました。
実は喋った内容をリアルタイムに認識させ表示することを元々目的としていたのですが(Googleの方ではそれも実装した)、PCからブラウザ経由でJuliusへリアルタイムに音声渡す→結果出力を出力するという方法がわからず断念したという経緯があります(これについては別途記述しますが)。直接マイクから音声を拾って音声認識というのは結構あったのですが。。
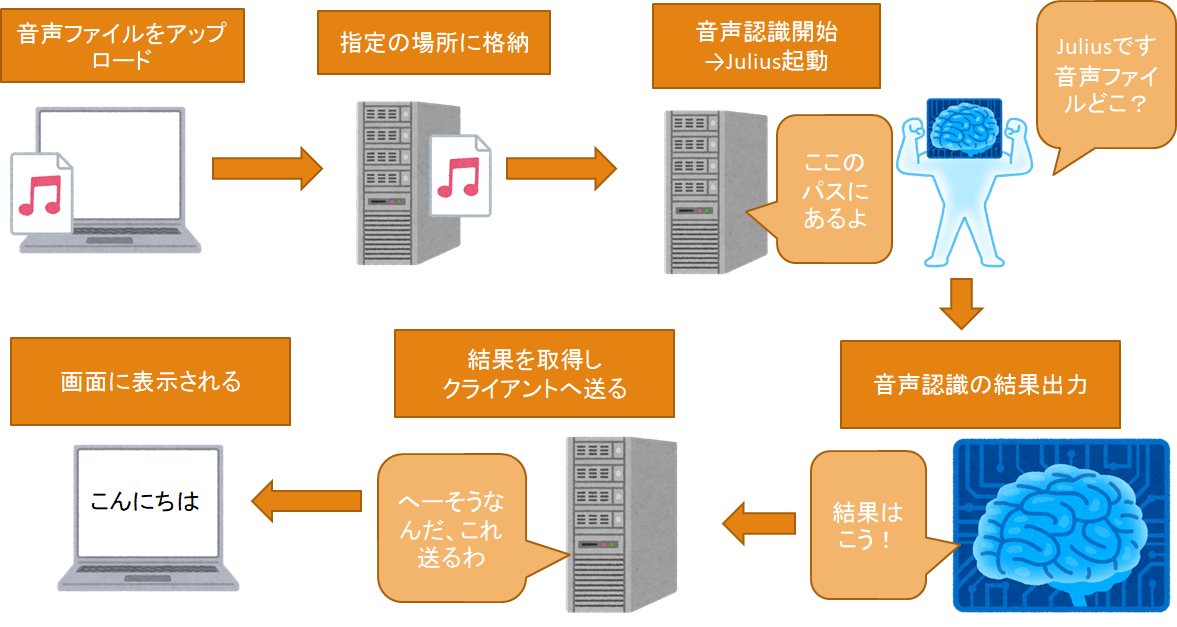
これを実現する為に、具体的には以下のことを行いました。
①Julius dictation-kit インストール
②Node.JSとその他必要なモジュールインストール
③https対応(とりあえずお試しなので自己証明)
④HTTPS,CSS,Javascriptを使ってブラウザ画面作成
⑤Node.JSでサーバ側処理を記述
とこんな具合です。すごい端折ってます(笑)
ちなみに③ですが、これはリアルタイム認識するときにchrome上からマイクをオンにして音声を取得するということをしたのですが、chromeの仕様上https通信でないとマイクアクセス許可できないらしく、この対応が入ってます。なので音声ファイルのみなら不要です。
正直意外とこの情報がなかなか検索してもヒットしなくて、ちょっとハマりました(なので備忘的な意味も兼ねて一応記載しておきました)。
また、全部を細かく書くのも難しいので、この記事では上記の中で私が実装するにあたってハマった部分や気になった部分をピックアップして記載していこうと思います。
Juliusインストール
何はともあれJuliusをインストールします。今回はdictation-kitを利用しました。※サーバのOSはCentOSです。
dictation-kitのデータはJulius公式からダウンロード可能です。
私は現時点で最新となっているVer.4.4を使用しました。
Ver.4.4はdictation-kitにJuliusも同梱されているので、とりあえずdictation-kitのzipだけ持ってくれば最低限Juliusを動作させることは可能です。
zip取得後、インストールするサーバの任意の場所にzipを配置し、以下のコマンドを実行します。
|
1 2 3 4 5 6 7 8 9 |
unzip dictation-kit-v4.4.zip unzip dictation-kit-v4.4.zip cd dictation-kit-v4.4 cd src tar xzvf julius-4.4.2.tar.gz cd julius-4.4.2 ./configure --prefix=/usr/local make make install |
とりあえずこれでサーバにJuliusが入りました。サーバに入ってJuliusを直接動かすのであれば、これで音声認識させることが可能です。
例えば音声ファイルを使って認識させる場合、以下のコマンドを叩くとJuliusが起動します。
|
1 |
julius -C /dictation-kitのあるパス/dictation-kit-v4.4/main.jconf -C /dictation-kitのあるパス/dictation-kit-v4.4/am-gmm.jconf -input rawfile |
オプション-inputで音声の入力方法を指定します。rawfileと音声ファイルを指定している為、起動時にダーっと色々文字が流れてから、ファイルの場所を聞かれます。
|
1 2 3 4 5 6 7 8 9 |
Notice for feature extraction (01), ************************************************************* * Cepstral mean normalization for batch decoding: * * per-utterance mean will be computed and applied. * ************************************************************* ------ ### read waveform input enter filename-> |
サーバ上に認識してほしい音声ファイルをアップしておき、その音声ファイル名を標準入力で指定します。
そうすると、以下の様に認識結果が出力されます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
### read waveform input enter filename->voice2.wav Stat: adin_file: input speechfile: voice2.wav Warning: strip: sample 281-297 has zero value, stripped Warning: strip: sample 385-401 has zero value, stripped Warning: strip: sample 488-505 has zero value, stripped Warning: strip: sample 587-604 has zero value, stripped Warning: strip: sample 1117-1132 has zero value, stripped Warning: strip: sample 84473-84498 has zero value, stripped Warning: strip: sample 84690-84706 has zero value, stripped Warning: strip: sample 84926-84944 has zero value, stripped STAT: 84936 samples (5.31 sec.) STAT: ### speech analysis (waveform -> MFCC) ### Recognition: 1st pass (LR beam) .................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................pass1_best: 文 に 含め 、 ヤン に 編ん で は 気 か 。 pass1_best_wordseq: <s> 文+名詞 に+助詞 含め+動詞 、+補助記号 ヤン+名詞 に+助詞 編ん+動詞 で+助詞 は+助詞 気+名詞 か+助詞 </s> pass1_best_phonemeseq: silB | b u N | n i | f u k u m e | sp | y a N | n i | a N | d e | w a | k i | k a | silE pass1_best_score: -16222.363281 ### Recognition: 2nd pass (RL heuristic best-first) WARNING: 00 _default: hypothesis stack exhausted, terminate search now STAT: 00 _default: 0 sentences have been found WARNING: 00 _default: got no candidates, search failed STAT: 00 _default: 148614 generated, 7717 pushed, 1291 nodes popped in 529 <search failed> ------ ### read waveform input |
認識の結果はさておき、音声ファイルから認識→結果取得までできました。最初にwarningがたくさんありますが、これは音声ファイルの最初の無音部分なので特に無視で問題ありません。(それにしても怪文書だ。。)
ちなみに音声ファイルについては、Julius公式で記載のある通り、以下のフォーマットでないと認識してくれません。
チャンネル数:1(モノラル)
サンプリングレート:16kHz
また、認識時のオプションが色々あり、例えば「-cutsilence」というオプションをつけると、一定の無音時間を文章の区切りと判断し、文章を区切って結果出力してくれます。
ただ私がやりたかったのはサーバから直接コマンドを叩いてではなく、ブラウザ上から音声を音声認識させることなので、まだしばらく続きます。。
結構長くなってきたので次回に続きます。。
- 【React】フロントエンドのテストコードを書いてみよう【Vitest】 - 2024-04-30
- Simple AWS DeepRacer Reward Function Using Waypoints - 2023-12-19
- Restrict S3 Bucket Access from Specified Resource - 2023-12-16
- Expand Amazon EBS Volume on EC2 Instance without Downtime - 2023-09-28
- Monitor OpenSearch Status On EC2 with CloudWatch Alarm - 2023-07-02
【採用情報】一緒に働く仲間を募集しています