音声認識エンジンの開発を行う側、ボランティアでプログラマ向けにディープラーニングを教えたりしているAI事業部の大橋です。
OpenAIが開発しているGPT-3という言語モデルのAPIが一般に公開されはじめて、反響を呼んでいるようなので、どんな事ができるのか、どう評価されているのかについて纏めてみる事にしました。
本当は実際に触ってみて、その実力を確認したいところですが、現在は潜在顧客やテックジャーナリストにしかAPIを公開していないようなので、今回は、その概要について記述したいと思います。
目次
GPT-3とは
まず、GPT-3についてですが、OpenAIが開発している言語モデルの最新版です。3とついているところからもわかるようにシリーズ化されており、今回の奴はバージョン3です。
ところで、これは余談ですが、OpenAIはイーロンマスクによって設立され、悪い奴が最初に最強のAIを開発してしまうと世の中にたいへん悪い影響があるだろうから、良い奴である我々が最初に最強のAIを開発しようという目的のために設立された非営利団体です。自分たちが100%良い奴と言い切ってしまっているあたりは危うさのある組織ですが、技術面では、言語モデルの世界ではGoogleとState-of-the-artを競い合っている実績があります。最近「100%良い奴」である事を止めることにしたのか、営利団体に鞍替えしたようです。
さて、本題のGPT-3ですが、言語モデルという型のモデルで、特徴はその巨大さです。
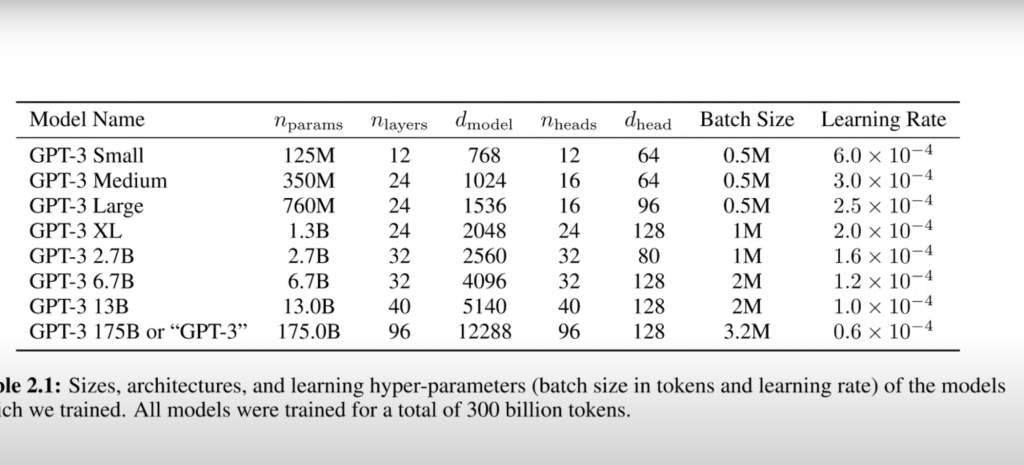
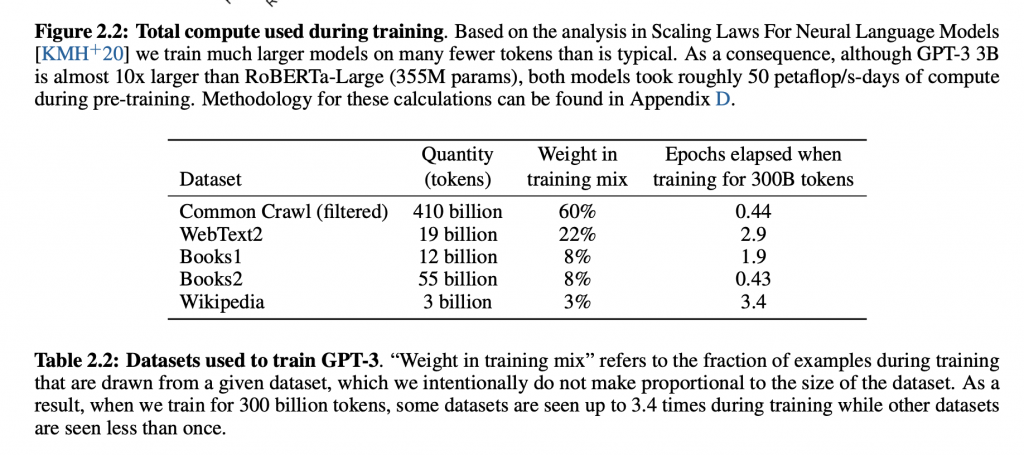
学習可能なパラメータの数、なんと175Bです。175Bは175,000,000,000のことですが、0が多過ぎて大きい数字なのか小さい数字なのかわかりません。でも、GPT-3の次に大型のモデルが13Bである事を考えるとちょっと前の類似モデルの10倍以上の規模であることがわかります。実は昨年公開したGPT-2は「その性能が凄過ぎて悪用されると困るので公開はしない」といって論文だけ発表して物議を醸したものなのですが、それが1.5Bだったことを考えると、とんでもない巨大モデルということが言えます。
またまた余談ですが、GoogleがBertというなかなかにクリエイティブなモデルを公開して当時のstate-of-the-artを塗り替えた時も、単純にモデルを巨大化させて抜き返した前科があります。社長が「俺たちは頭を使うよりも金を使おう、より巨大なモデルにより多くのデータを投入し、あとはコンピューテーションに金を使おう」と言ったかどうかはわかりませんが、実際に行われたのは正にそんな感じで、物量作戦で作り上げられたのがGPT-2です。なので、OpenAI、またやらかしたか、といった感じですね。
言語モデルとは
結論からいうと、インプットされたテキストを元にその続きを予測するモデルです。名前が立派なので崇高な知性をイメージするのですが、統計的に次の文字はこれっぽいっていうのを出しているだけのモデルです。
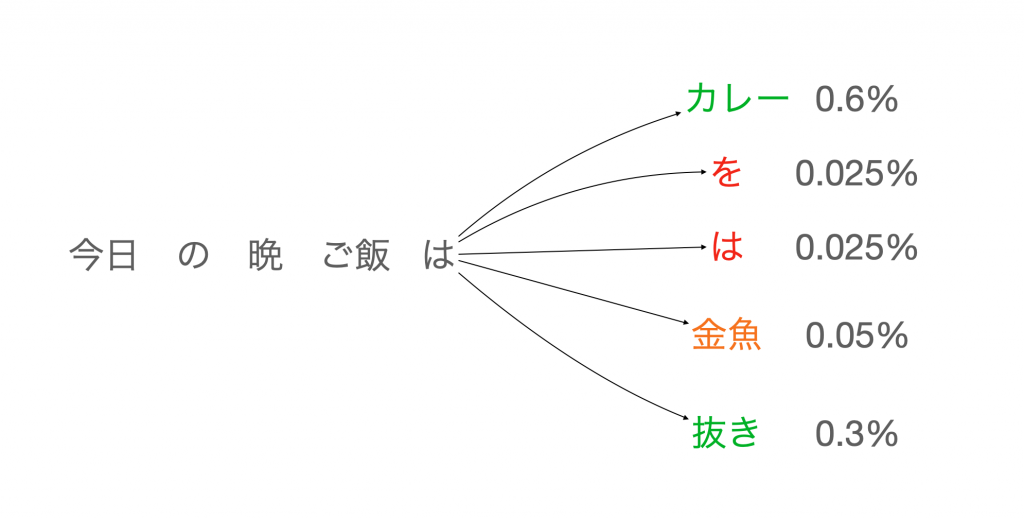
上の図は言語モデルの例ですが、「今日の晩ご飯は」をインプットとして、それに続き単語をアウトプットとして予測します。当然ながら食べ物の可能性が高く、食べ物でなくても可能性のある単語はそれなりの確率で割り当てられます。文章として成り立たないような単語はほぼ0%ということになります。
一見すると、ただ単にリソースを多くぶっこんだだけに思えるGPT-3ですが、結果として、もの凄いものに仕上がっており、その使い方に関しては極めてクリエイティブなアイデアが提示されています。
ファインチューニングの必要なし?
ファインチューニングとは
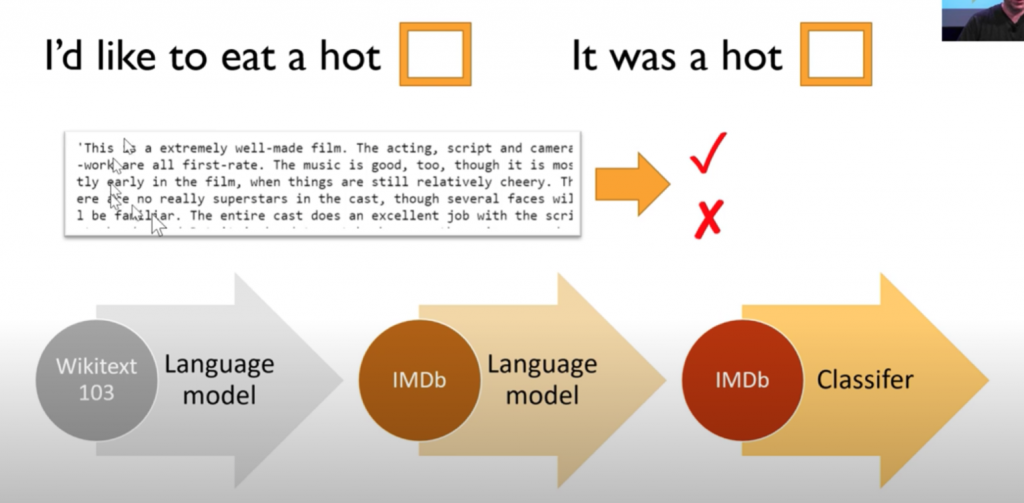
画像処理では結構前からごく一般的な手法で、言語処理ではようやく使われ始めたくらいのものなのですが、GPT-3はファインチューニング無しで、いきなり様々な用途に使えて、性能も悪くない、というのが論文の主張です。
その中で、ファインチューニングはしないものの、クエリーの仕方に工夫があり、そのクエリーの仕方に「Zero Shot」「One Shot」「Few Shot」などという名前を付けています。実は論文のタイトルも「Language Models are Few-Shot Learners」です。
Zero-Shot、One-Shot、Few-Shot とは
Zero-Shot
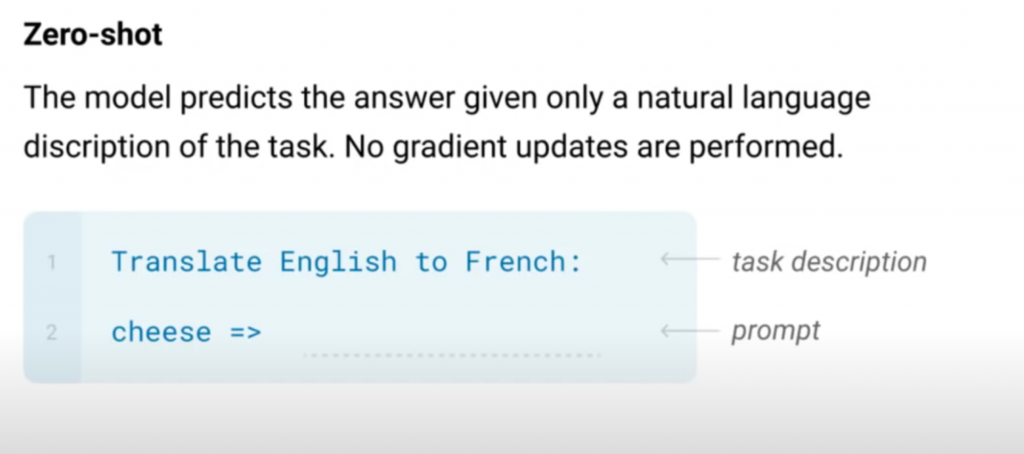
上の図では、「Translate English to French: 改行コードcheese =>」がインプットです。お題に当たる部分は英語からフランス語への翻訳で、最後にcheeseが与えられています。正解はフランス語版のcheeseです。
なんと、問題と回答欄のようなフォーマットを言葉(自然言語)で与えています。
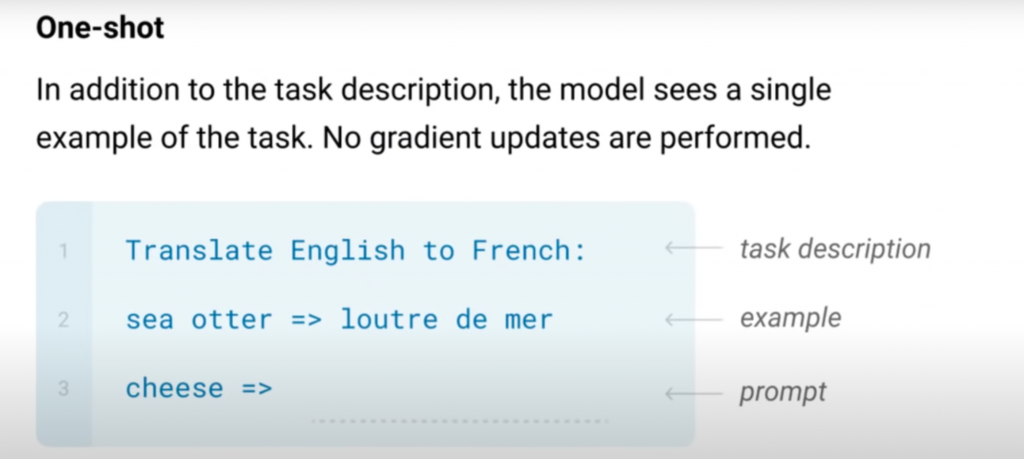
では、One-Shotとは何でしょうか。
One-Shot
もう、お分かりだと思いますが、Few-Shotsの例も載っけておきます。
Few-Shots

画期的なところは、どんな事も一つのモデルで出来てしまうところです。
例えば、ファインチューニングを使って法律関連の文書分類モデルをつくるケースであれば、ウィキペディアでベースとなる言語モデルの学習、法律文書による言語モデルのファインチューニング、そして法律文書による分類モデルの学習という3ステップが必要になるわけですが、最後のステップは、言語モデルではなく分類モデルなので、文章と分類したいクラスのデータセットの用意が必須です。データセットは基本、頑張ってアノテーションして拵える事になります。
クエリーの仕方も画期的ですが、もし、別データセットを用意する必要がなくなるのであれば、その点も画期的ですね。
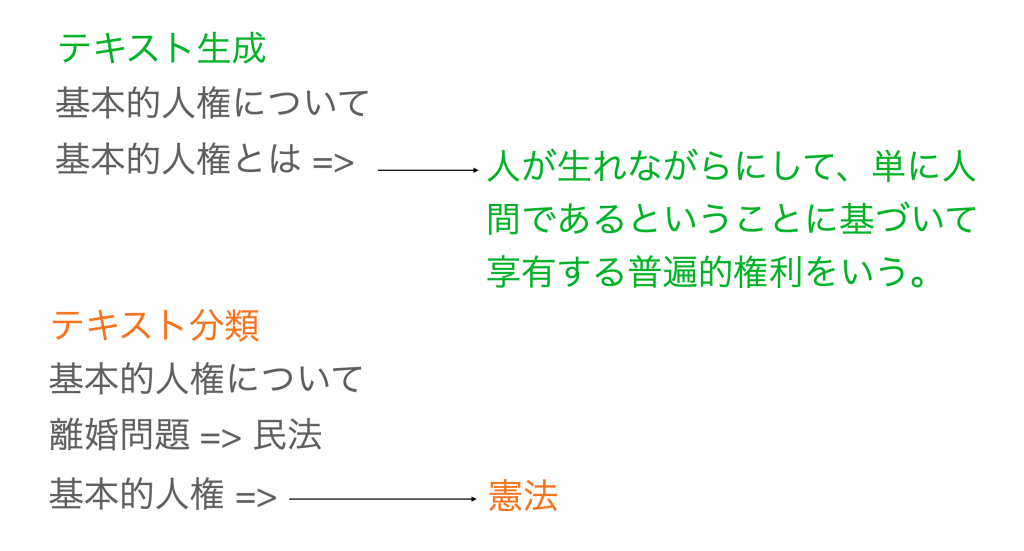
API活用事例
GPT-3によるプログラムのコードを自動生成
文章の自動生成
質問と回答
APIを試してみたユーザーからの評価
試してみた方からは概ね驚きの声が聞こえてきますが、一方で言語モデルの限界も指摘されています。まず、簡単な算数もできるようになったものの、ウェブ上に問題集が落ちているような簡単なものしか解けず、論理を理解しているというよりは答えを記憶している可能性が高いです。また、ファインチューニングをしなくてもそれなりの精度が出る、分類モデルなどを特別に準備する必要がないというのは凄い事だと思いますが、ファインチューニングから個別モデルの学習を行ったモデルの性能には肉薄はしていますが、勝ててはいません。膨大なデータを膨大なモデルに食わせれば、どこかで統計的なパターン以上の論理を学習するのではないかという期待は今のところ現実のものとはなっていないようです。
とはいえ、文章を生成するというオリジナルのタスクに関しての性能は凄まじく、フェイクニュースの性能がワンランク上がってしまいそうですね。
そう言えばモデルのアーキテクチャに関してですが、実はGoogleのBertもOpenAIのGPTもTransformerという同じ部品をベースとしています。そこら辺の技術的な話はまたの機会に。
- 【React】フロントエンドのテストコードを書いてみよう【Vitest】 - 2024-04-30
- Simple AWS DeepRacer Reward Function Using Waypoints - 2023-12-19
- Restrict S3 Bucket Access from Specified Resource - 2023-12-16
- Expand Amazon EBS Volume on EC2 Instance without Downtime - 2023-09-28
- Monitor OpenSearch Status On EC2 with CloudWatch Alarm - 2023-07-02
【採用情報】一緒に働く仲間を募集しています