こんにちは。ギークフィードの高橋敦史です。
業務システムあるあるに「エクセルで出力して」という要望があります。
不思議とWordの要望は少なくパワポに至っては聞かれたこともありませんが、Excelの入出力機能はなかなか需要がなくならないようです。
そこで我々エンジニアがExcel形式に対応したライブラリを使って開発することになりますが、作り込むうちに思わぬところで壁に当たったり、ほんのレイアウト調整程度で工数が溶けることもしばしば。
そんなエクセルさんと仲良くなるため、xlsx形式内部のデータ構造と調べ方を紹介しようと思います。
※xls形式や各種ライブラリの使い方には触れません。
目次
Excel形式のファイル構造を一言で
十数年前までエクセルといえば「.xls」を拡張子に持ち、バイナリ形式で保存されるファイルでした。
それがExcel2007の登場と共に「.xlsx」拡張子が広まり、XML形式+zip圧縮が標準となっています。
つまり、現在の標準であるxlsx形式のファイルはzip解凍でき、中身は基本的にXMLということになります。
※仕様は「Office Open XML」として国際標準化されています。
xlsxファイルの中身を展開する
まず適当なXLSX形式のファイルを用意します。
新しいファイルを作成し、2シート設けて下図のような編集を加えておきます。
手入力したり、セルをコピペしたり、セル参照も設定、セルの入力書式を少々変更、あとは画像も挿入しておきましょうか。意味不明な場所ですが気にせず。。
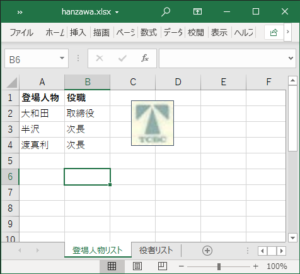
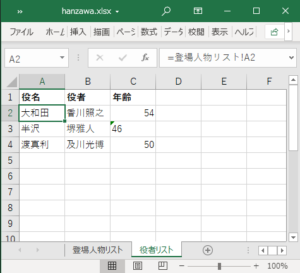
保存して閉じたら、次に拡張子を「.zip」に変更します。
Windows環境で拡張子を表示しない設定にしている場合は、一時的に設定を変えて拡張子を表示してください。
拡張子変更の際、「ファイルが使えなくなる可能性」とOSから警告されても無視します。
拡張子が変わったら、あとは普通のzipファイルとして解凍すると、以下のようなファイル群が展開されます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
┬ _rels │ └ .rels ├ docProps │ ├ app.xml │ └ core.xml ├ xl │ ├ _rels │ │ └ workbook.xml.rels │ ├ drawings │ │ ├ _rels │ │ │ └ drawing1.xml.rels │ │ └ drawing1.xml │ ├ media │ │ └ image1.jpg │ ├ printerSettings │ │ ├ printerSettings1.bin │ │ └ printerSettings2.bin │ ├ theme │ │ └ theme1.xml │ ├ worksheets │ │ ├ _rels │ │ │ ├ sheet1.xml.rels │ │ │ └ sheet2.xml.rels │ │ ├ sheet1.xml │ │ └ sheet2.xml │ ├ calcChain.xml │ ├ sharedStrings.xml │ ├ styles.xml │ └ workbook.xml └ [Content_Types].xml |
紙面の都合上、主要なものだけピックアップして紹介します。
| _rels | (階層内の)各パーツの関連性を定義 |
| xl/media | 挿入した画像ファイルの実体を格納 |
| xl/sharedStrings.xml | 全シートの全セルに入力された文字列を集約 |
| xl/worksheets/sheetN.xml | 各シートのデータを収納 |
つまりsheetN.xmlがシートの本体データで、装飾やテキスト・画像コンテンツはそれぞれ別の場所に保存されており、その参照関係がrelsファイルで定義されているという構造になっています。
XMLファイルを覗き見る
では具体的にXMLを覗いてみましょう。
そのままでは見づらいので、XMLエディタで整形します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 |
<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <sst xmlns="http://schemas.openxmlformats.org/spreadsheetml/2006/main" count="15" uniqueCount="14"> <si> <t>登場人物</t> <rPh sb="0" eb="4"> <t>トウジョウジンブツ</t> </rPh> <phoneticPr fontId="1"/> </si> <si> <t>役職</t> <rPh sb="0" eb="2"> <t>ヤクショクショク</t> </rPh> <phoneticPr fontId="1"/> </si> <si> <t>大和田</t> <phoneticPr fontId="1"/> </si> <si> <t>半沢</t> <phoneticPr fontId="1"/> </si> <si> <t>渡真利</t> <phoneticPr fontId="1"/> </si> <si> <t>取締役</t> <phoneticPr fontId="1"/> </si> <si> <t>次長</t> <phoneticPr fontId="1"/> </si> <si> <t>役者</t> <rPh sb="0" eb="2"> <t>ヤクシャ</t> </rPh> <phoneticPr fontId="1"/> </si> <si> <t>堺雅人</t> <phoneticPr fontId="1"/> </si> <si> <t>及川光博</t> <phoneticPr fontId="1"/> </si> <si> <t>香川照之</t> <phoneticPr fontId="1"/> </si> <si> <t>役名</t> <rPh sb="0" eb="2"> <t>ヤクメイ</t> </rPh> <phoneticPr fontId="1"/> </si> <si> <t>年齢</t> <rPh sb="0" eb="2"> <t>ネンレイ</t> </rPh> <phoneticPr fontId="1"/> </si> <si> <t>46</t> <phoneticPr fontId="1"/> </si> </sst> |
ここには全シートのテキストが集約されています。
しかしよく見ると、「次長」は2つのセルに入力されていますが、sharedStrings.xml内には一つしかありません。
また、年齢の「54」と「50」も見当たりません。一方で「46」だけは存在しますが、これはセルの書式を文字列にして入力したためです。
「役職」に対する読み方が「ヤクショクショク」となってますが、これは入力中に失敗して編集したものが残ってしまったようです。別セルにもう一度ミスなく「役職」と入力した場合は、異なるデータとして保存されます。
sheet1.xml
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <worksheet xmlns="http://schemas.openxmlformats.org/spreadsheetml/2006/main" xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships" xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006" mc:Ignorable="x14ac xr xr2 xr3" xmlns:x14ac="http://schemas.microsoft.com/office/spreadsheetml/2009/9/ac" xmlns:xr="http://schemas.microsoft.com/office/spreadsheetml/2014/revision" xmlns:xr2="http://schemas.microsoft.com/office/spreadsheetml/2015/revision2" xmlns:xr3="http://schemas.microsoft.com/office/spreadsheetml/2016/revision3" xr:uid="{00000000-0001-0000-0000-000000000000}"> <dimension ref="A1:B4"/> <sheetViews> <sheetView tabSelected="1" workbookViewId="0"> <selection activeCell="B6" sqref="B6"/> </sheetView> </sheetViews> <sheetFormatPr defaultRowHeight="18.75"/> <sheetData> <row r="1" spans="1:2"> <c r="A1" s="1" t="s"> <v>0</v> </c> <c r="B1" s="1" t="s"> <v>1</v> </c> </row> <row r="2" spans="1:2"> <c r="A2" t="s"> <v>2</v> </c> <c r="B2" t="s"> <v>5</v> </c> </row> <row r="3" spans="1:2"> <c r="A3" t="s"> <v>3</v> </c> <c r="B3" t="s"> <v>6</v> </c> </row> <row r="4" spans="1:2"> <c r="A4" t="s"> <v>4</v> </c> <c r="B4" t="s"> <v>6</v> </c> </row> </sheetData> <phoneticPr fontId="1"/> <pageMargins left="0.7" right="0.7" top="0.75" bottom="0.75" header="0.3" footer="0.3"/> <pageSetup paperSize="9" orientation="portrait" horizontalDpi="300" verticalDpi="300" r:id="rId1"/> <drawing r:id="rId2"/> </worksheet> |
データは行ごとにまとめられていますね。
セルのデータは 0 のように数値になっていますが、これはsharedStrings.xmlの0番目の要素を指し示しています。
実は「次長」のセルはコピペしていたのですが、XMLを見ると同じ参照先(=6)になっています。
最後の方に
<drawing r:id="rId2"/> というのがありますが、これが挿入した画像の定義情報です。
sheet2.xml
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 |
<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <worksheet xmlns="http://schemas.openxmlformats.org/spreadsheetml/2006/main" xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships" xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006" mc:Ignorable="x14ac xr xr2 xr3" xmlns:x14ac="http://schemas.microsoft.com/office/spreadsheetml/2009/9/ac" xmlns:xr="http://schemas.microsoft.com/office/spreadsheetml/2014/revision" xmlns:xr2="http://schemas.microsoft.com/office/spreadsheetml/2015/revision2" xmlns:xr3="http://schemas.microsoft.com/office/spreadsheetml/2016/revision3" xr:uid="{5F642AE3-865D-46CE-99C1-32B6DAEDC738}"> <dimension ref="A1:C4"/> <sheetViews> <sheetView workbookViewId="0"> <selection activeCell="B6" sqref="B6"/> </sheetView> </sheetViews> <sheetFormatPr defaultRowHeight="18.75"/> <sheetData> <row r="1" spans="1:3"> <c r="A1" s="1" t="s"> <v>11</v> </c> <c r="B1" s="1" t="s"> <v>7</v> </c> <c r="C1" s="1" t="s"> <v>12</v> </c> </row> <row r="2" spans="1:3"> <c r="A2" t="str"> <f>登場人物リスト!A2</f> <v>大和田</v> </c> <c r="B2" t="s"> <v>10</v> </c> <c r="C2"> <v>54</v> </c> </row> <row r="3" spans="1:3"> <c r="A3" t="str"> <f>登場人物リスト!A3</f> <v>半沢</v> </c> <c r="B3" t="s"> <v>8</v> </c> <c r="C3" s="2" t="s"> <v>13</v> </c> </row> <row r="4" spans="1:3"> <c r="A4" t="str"> <f>登場人物リスト!A4</f> <v>渡真利</v> </c> <c r="B4" t="s"> <v>9</v> </c> <c r="C4"> <v>50</v> </c> </row> </sheetData> <phoneticPr fontId="1"/> <pageMargins left="0.7" right="0.7" top="0.75" bottom="0.75" header="0.3" footer="0.3"/> <pageSetup paperSize="9" orientation="portrait" horizontalDpi="300" verticalDpi="300" r:id="rId1"/> </worksheet> |
A列は参照設定をしていたので、データも参照先が入っています。
先程見当たらなかった年齢の「54」と「40」は 54 のように直接保存されていました。
sheet1.xml.rels
|
1 2 3 4 5 6 7 |
<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships"> <Relationship Id="rId2" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/drawing" Target="../drawings/drawing1.xml"/> <Relationship Id="rId1" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/printerSettings" Target="../printerSettings/printerSettings1.bin"/> </Relationships> |
Id=”rId2″ のTargetとしてdrawing1.xmlが定義されています。先程sheet1.xmlで読み込まれていたものは、このリレーションシップを介して実体と繋がります。
さて、一通り主要なXMLにざっと目を通しました。
これでライブラリを使って実装する際も、関数の裏側でどのような操作が行われているか少しイメージが湧くのではないでしょうか。
データ量の多いExcelファイルの場合などロードするまでに時間がかかりますが、sharedStrings.xmlの仕組みが分かっていれば、なぜアクティブシートだけロードするのが難しいか理由が納得できると思います。
気持ちの悪い仕様
余談ですが、workbook.xml の中にこんな箇所があります。
|
1 2 3 4 5 6 |
<mc:AlternateContent xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006"> <mc:Choice Requires="x15"> <x15ac:absPath url="C:\Users\atsushi\Documents\GeekFeed\Excel解体\実験場\" xmlns:x15ac="http://schemas.microsoft.com/office/spreadsheetml/2010/11/ac"/> </mc:Choice> </mc:AlternateContent> |
添付資料でファイルを送ることなど普通にありますが、こんなところにローカルのパスが埋め込まれてたりするんですね。思わぬところでユーザ名やフォルダ分類がダダ漏れです。。
Excelのデータ構造を調べてみて
今回ご紹介したのは、ごくシンプルなxlsxファイルの一握りの情報でした。手順は簡単なので一度手元のPCで遊んでみてください。(もちろん壊れてもよいファイルで!)
変更後に差分を見たり、XMLを直接編集したものをzip化してxlsxに戻してみたり、操作に慣れておくと急な対応時に焦らずに済みます。
なお、Wordも同様のやり方でXMLに解体することができます。
試しに解体してみるとわかりますが、Wordの場合は何というかデザイン要素が半端なく入れ子状態になっていて、余計な要素を除去するところから始まる苦行の道になっています。
文字を打ち込んで、デザイン変えて、文字を削除すると空のデザインだけが残っているという。。
Excelがデータ中心なのに対し、Wordは装飾中心なのかなと個人的に思います。
ということでWord編の予定はありませんw
- 【React】フロントエンドのテストコードを書いてみよう【Vitest】 - 2024-04-30
- Simple AWS DeepRacer Reward Function Using Waypoints - 2023-12-19
- Restrict S3 Bucket Access from Specified Resource - 2023-12-16
- Expand Amazon EBS Volume on EC2 Instance without Downtime - 2023-09-28
- Monitor OpenSearch Status On EC2 with CloudWatch Alarm - 2023-07-02
【採用情報】一緒に働く仲間を募集しています