エンジニアのyokomachiです。
先日Amazon Connectの全リージョンでZero-ETLによるデータレイクがGAされたので簡単に試してみたいと思います。
Amazon Connect provides Zero-ETL analytics data lake to access contact center data – AWS
目次
Zero-ETLとは
まずはそもそもZero-ETLとはどういうことかという点から整理したいと思います。
ETLとはExtract(抽出)、Transform(変換)、Load(格納)というデータを分析などに扱いやすくするために加工するプロセスのことを指しています。
Amazon Connectにおいては、CTR(Contact Trace Record)やAgent Event Streams、あるいはCloudwatchなどに出力されるフローログなどのデータソースがあり、それらを分析ツールで使う場合にはユーザー自身がKinesisやGlue、LambdaによるETLのパイプラインを構築し、AthenaやQuicksightなどによるクエリ・可視化などを行うことが多かったです。
今回提供されたデータレイクがZero-ETLということは、ユーザー側でETLのデータパイプラインを構築・管理する必要がなく(あるいは少なく)、
分析のためのデータに直接的にアクセスすることができるということになります。
ゼロ ETL とは何ですか? – ゼロ ETL の説明 – AWS
本記事ではAmazon ConnectのZero-ETLを試してみますが、そのほかのAWSサービスでもZero-ETL関連のアップデートが公開されており、
2023/12時点の情報となりますがサーバーワークスさんの記事が参考になります。
zero-ETL関連アップデートまとめ(2023/12/7時点) – サーバーワークスエンジニアブログ
Zero-ETLを試してみる
それでは実際にAmazon ConnectのZero-ETLのデータアクセスを試してみたいと思います。
なお、公式のドキュメントではこちらに使用開始方法が記載されています。
Analytics data lake – Amazon Connect
データレイクの有効化
まずはAmazon Connectのインスタンス管理メニューから「分析ツール」を選択します。
「データレイク」という設定項目の右上の「データ共有の追加」ボタンを選択します。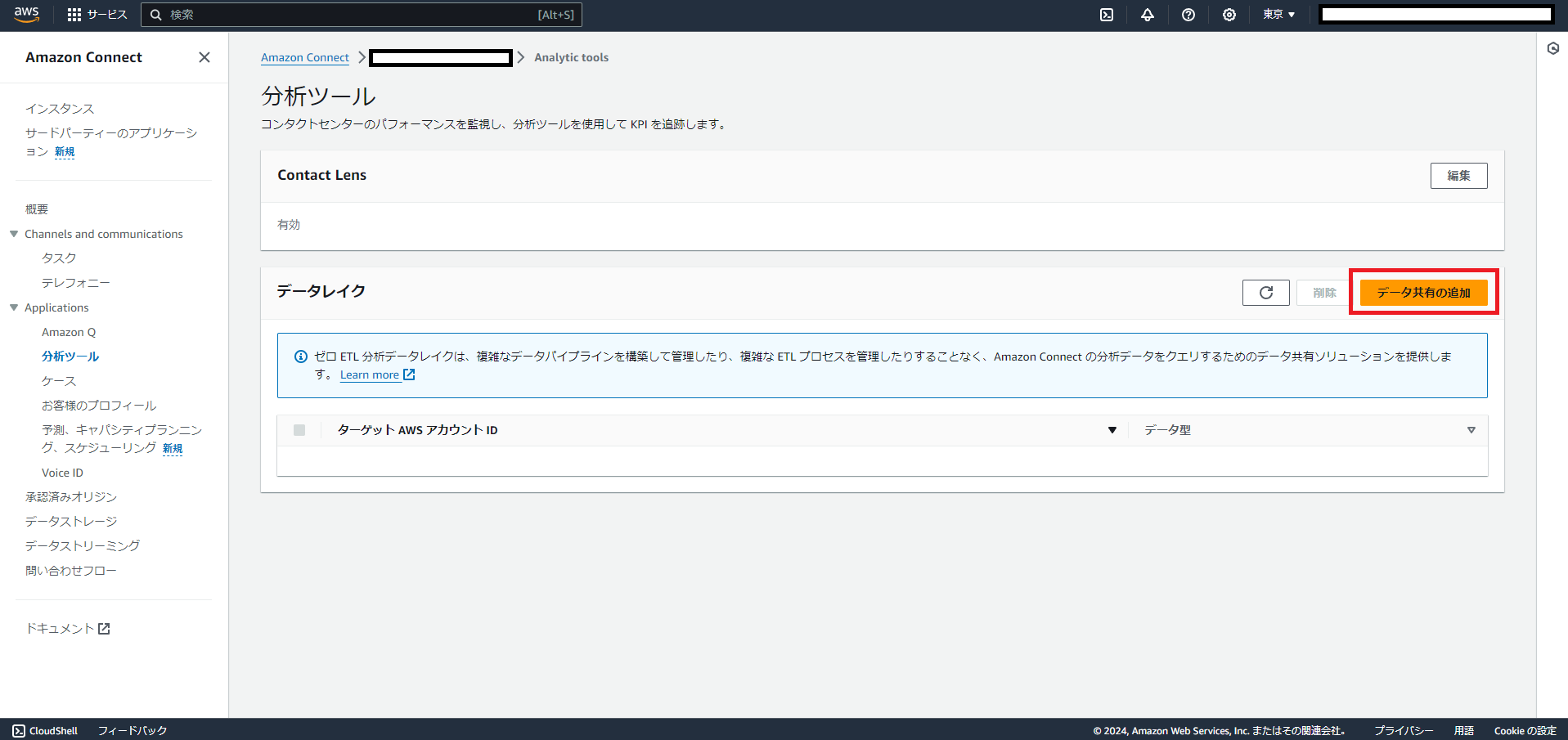
「データ共有の追加」ダイアログが表示されるので共有先のAWSアカウントIDと、共有するデータのタイプを選択します。
ということはつまりここで他のAWSに対してデータアクセスの許可ができるということですね。
今回はAmazon Connectをホストしているのと同じAWSアカウントからアクセスします。
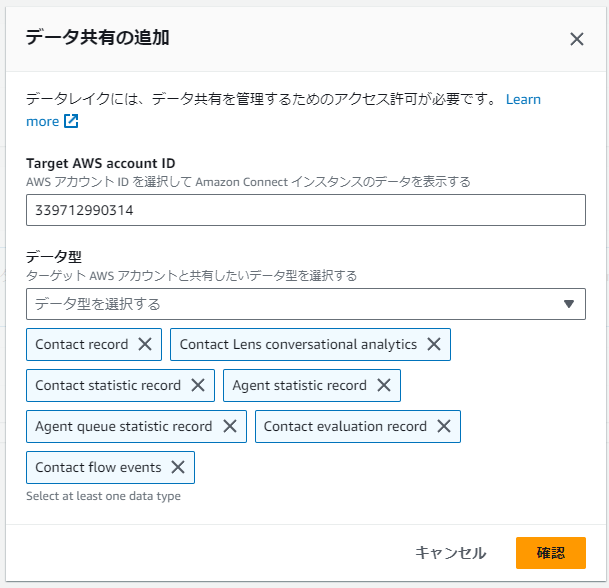
なお、データタイプの詳細については以下のページにまとめられています。
Data Type Definitions – Amazon Connect
簡単に各データタイプの概要を書くと以下の通りとなります。
Contacts Record
・・・CTRに似ていそう
Contact Lens Conversational Analytics
・・・Contact Lensによる会話の時間やスピード、感情分析のデータ(文字起こしは含まれないらしい)
Contact Statistic Record
・・・コンタクトの分析データ。Contacts Recordがコンタクトに紐づくデータの集合なのに対して、こちらはコンタクトの状態そのもののデータ、のように見える。
Agent Queue Statistic Record
・・・コンタクトに対するエージェントの振る舞いに関する分析データ。通話時間や受話した数など
Agent Statistic Record
・・・エージェントのステータスに関するデータ。Availableやカスタムステータスの時間など
Contact Evaluation Record
・・・コンタクトの評価に関するデータ。
Contact Flow Events
・・・コンタクトが紐づけられたフローに関するデータ
Resource Access Managerでリソース共有を承認する
続いてRAM(Resource Access Manager)のページを開きます。
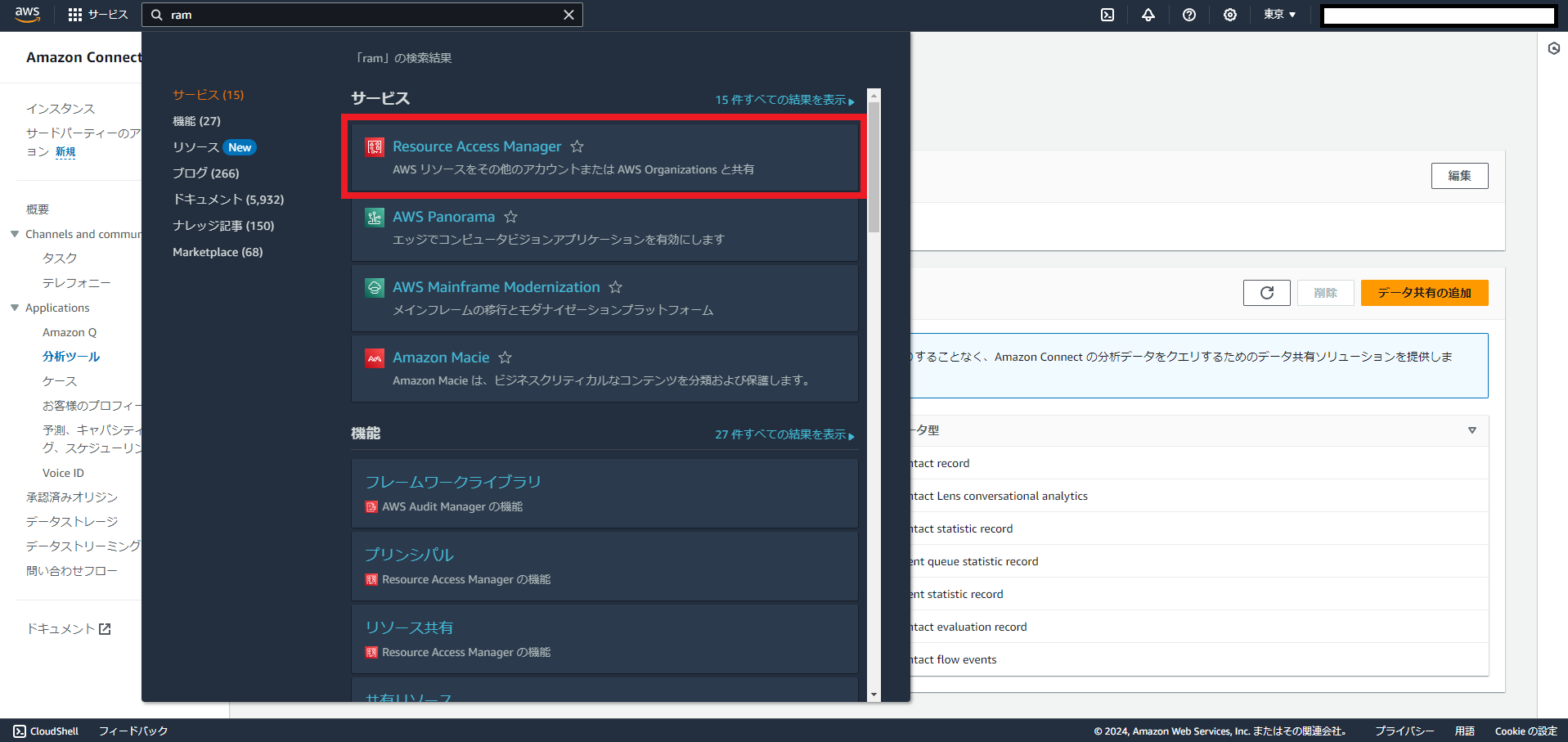
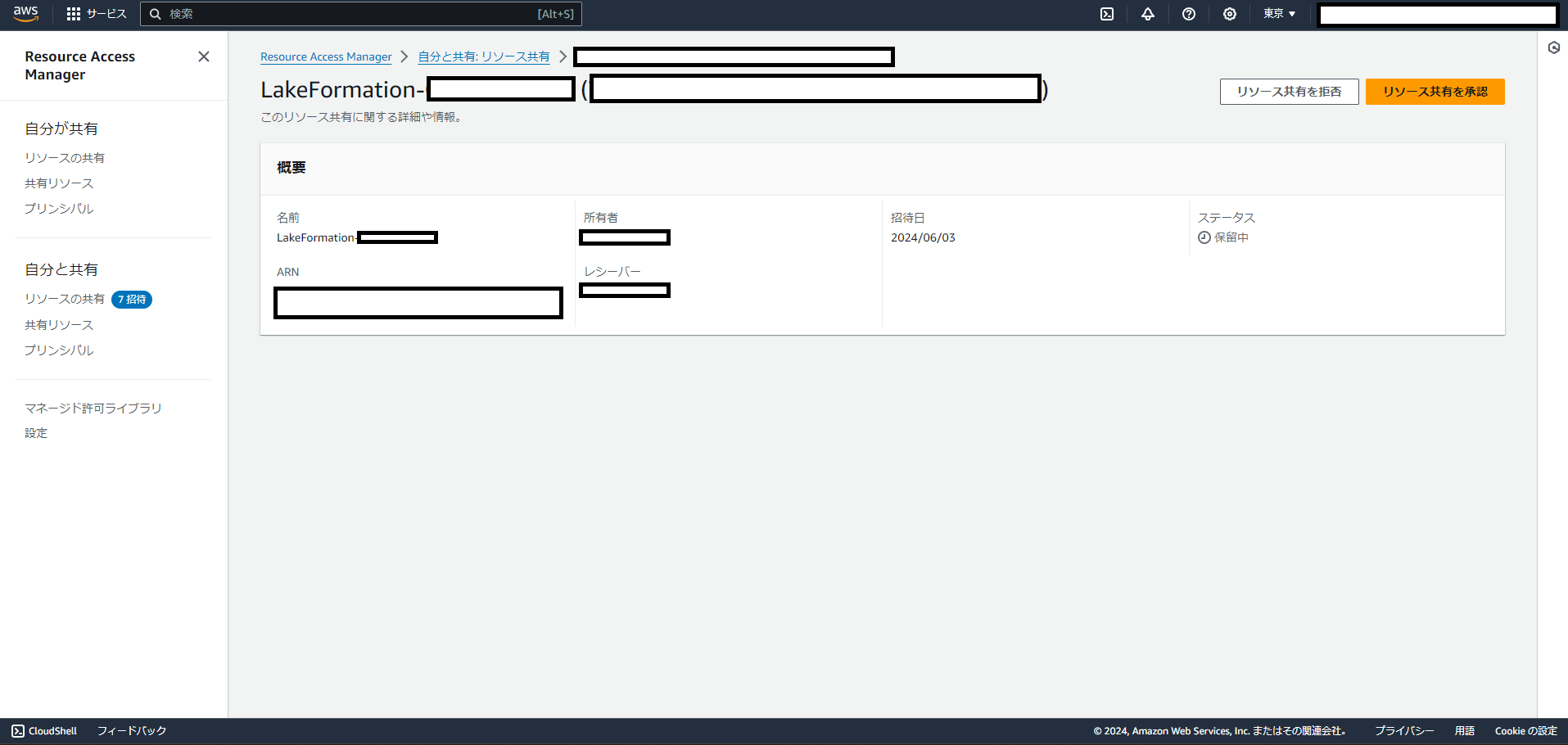
すると先ほど共有したデータタイプごとにリソース共有のリストができているので、すべて「リソース共有を承認」します。
Lake Formationでテーブルを作る
RAMですべてのリソース共有のステータスをアクティブにしたのち、今度はLake Formationを開きます。
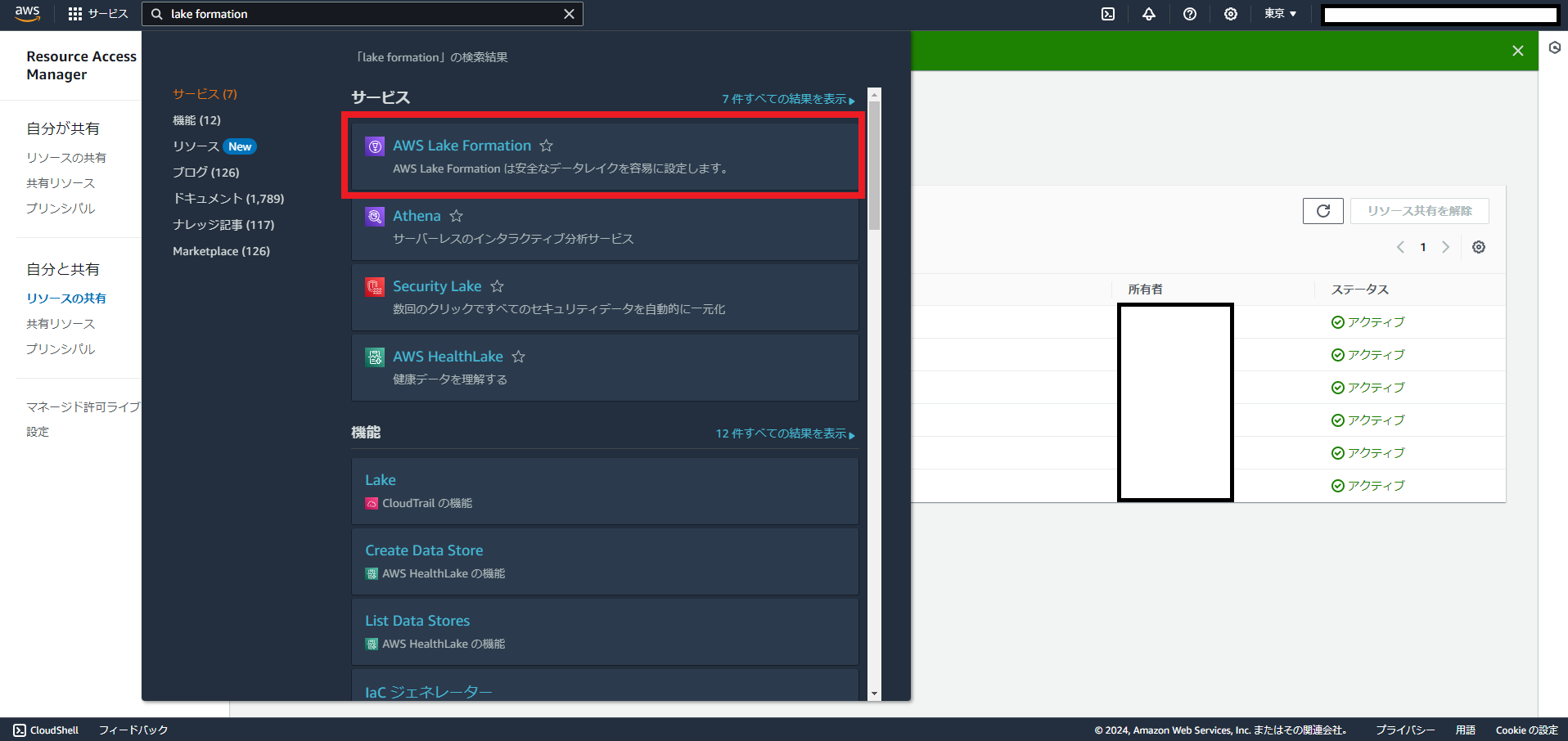
Lake Formationの「Table」メニューを開き、「Create Table」をクリックします。
(画像は関係ないデータがあったのでマスクしています)
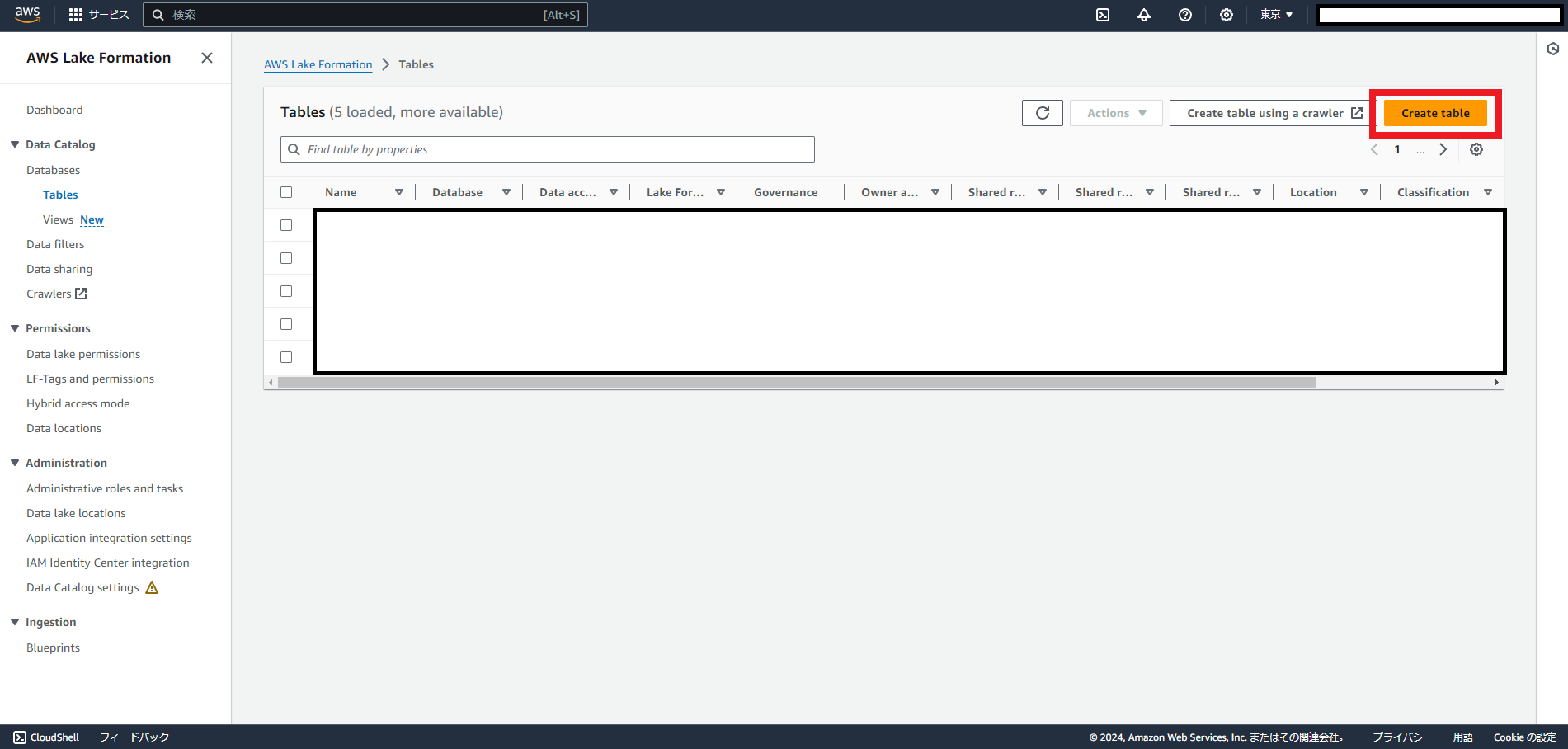
先ほど共有したリソースをリンクとしてテーブルを作成します。
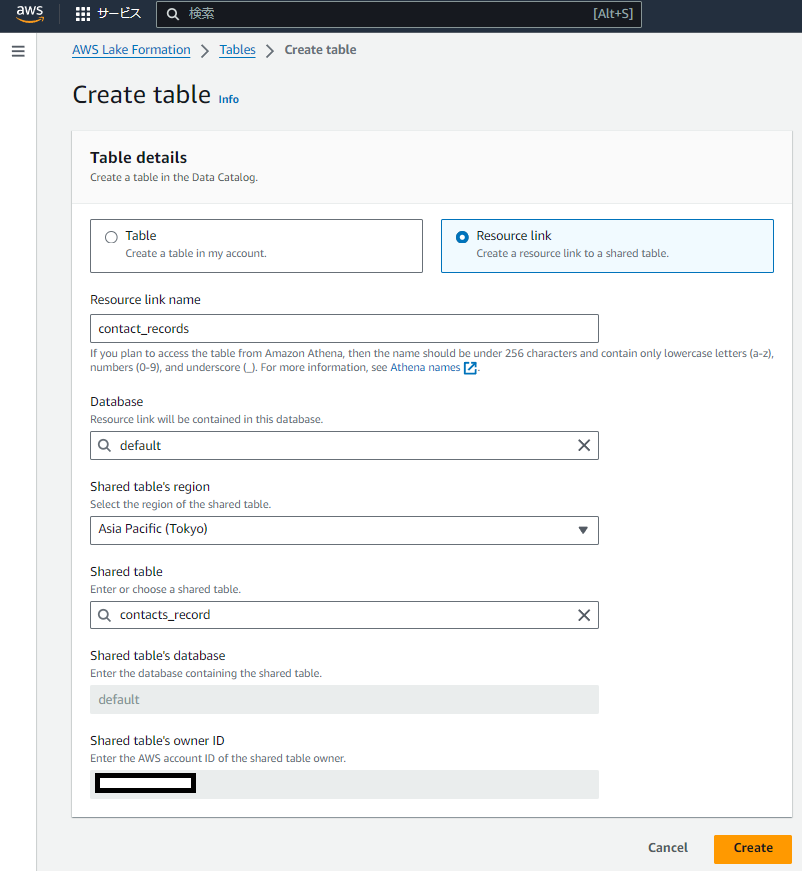
新しくテーブルが作られたことが確認できました。
以上でデータアクセスの準備は整いました!
Athenaからクエリしてみる
では今回作成したテーブルに対してAthenaからクエリをしてみます。
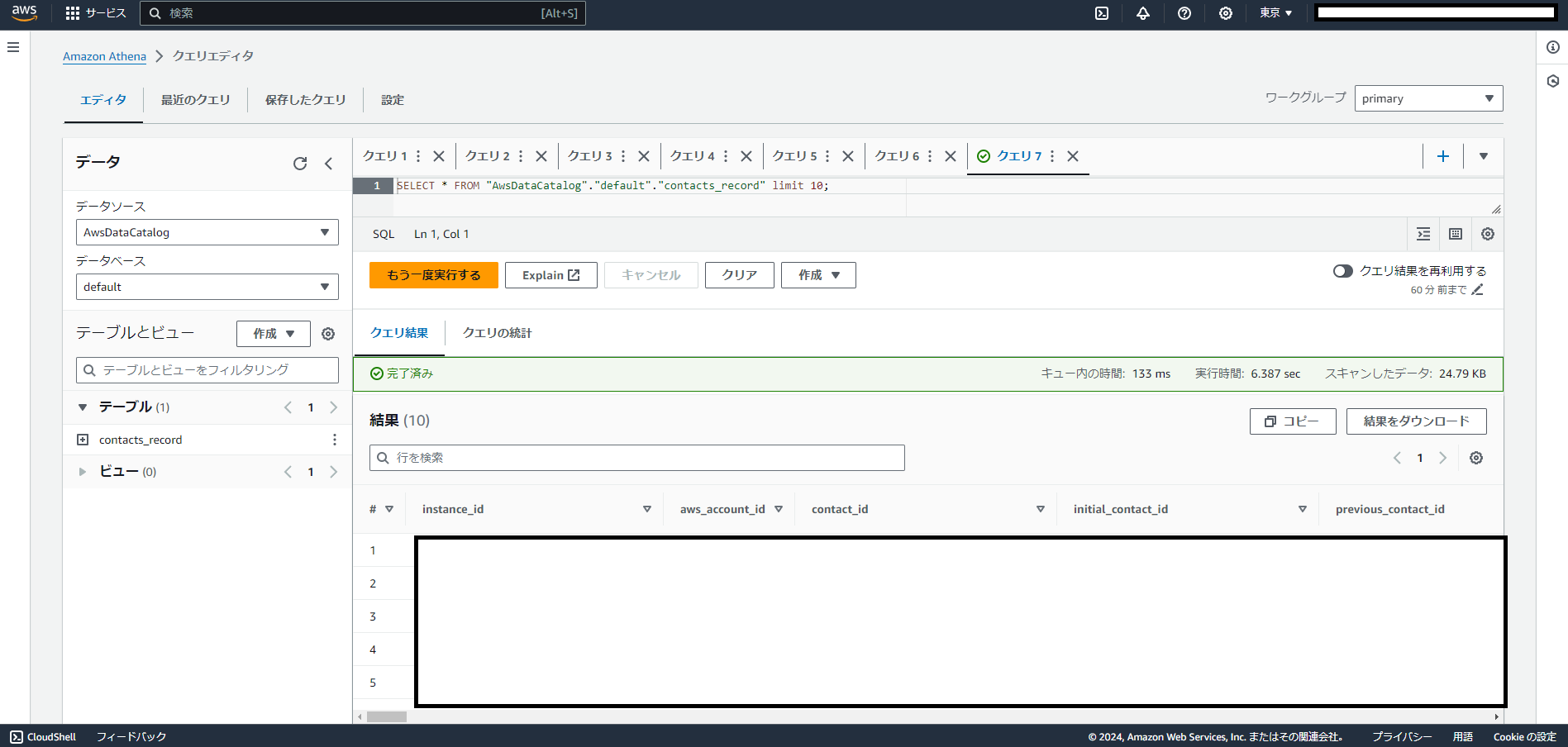
アクセスできていますね!
本来であればKinesisでデータのストリーミングを設定してS3に保管し、GlueでCrawlerやTableを作成するという工程を手動で行っていたETLのプロセスですが、
今回のZero-ETLの方法では難しい設定などは特になくコンタクトのレコードにアクセスできることが確認できました。
おまけ
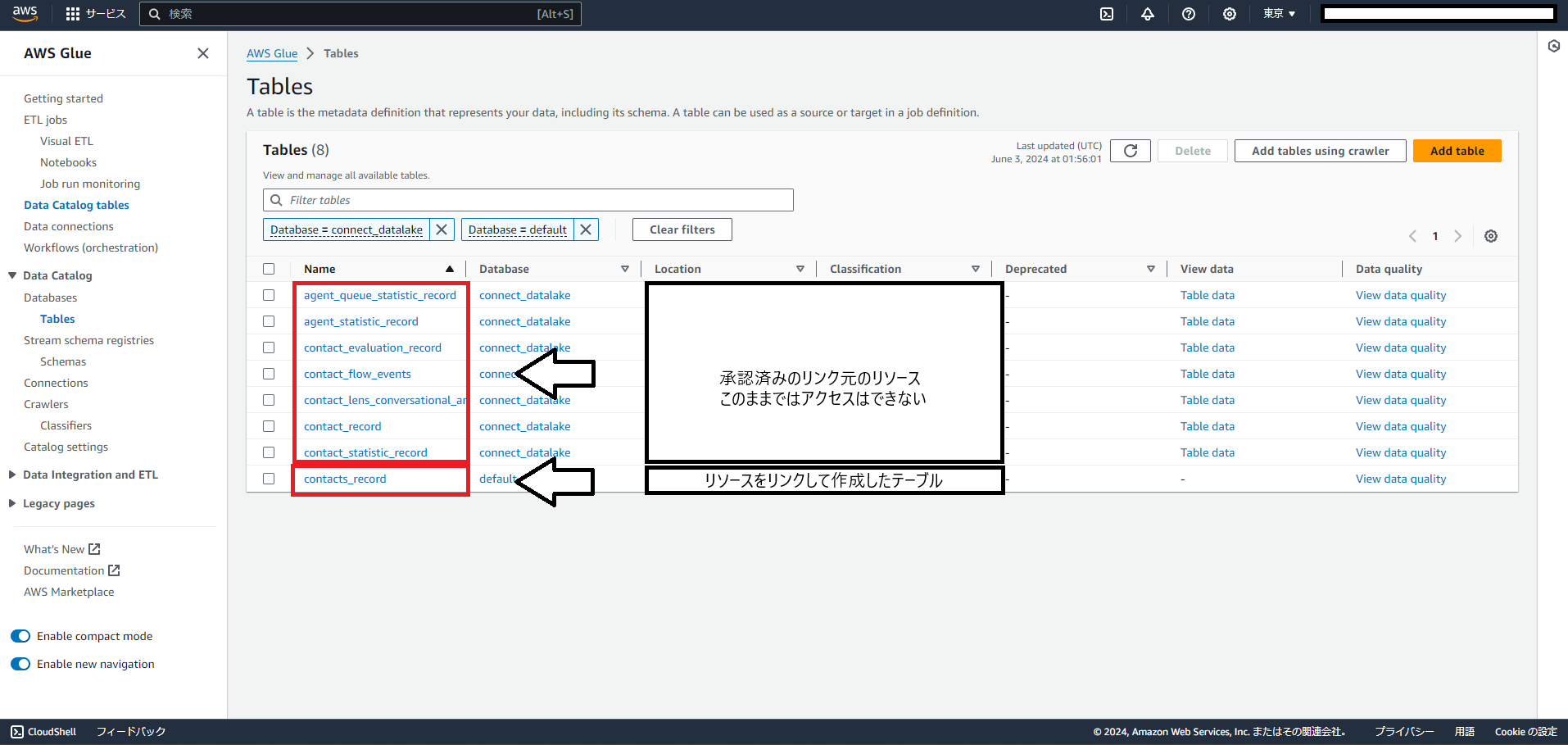
今回初めてLake Formationを触ったのですが、TableのページはGlueのサービスページとリンクしているようですね。
試しにGlueのTableページに飛んでみると、今回リンクして作成したテーブル以外にも、承認しただけでリンクはしていないリソースも表示されていました。
※今回すべてのデータタイプを共有・承認したが、実際にリンクを作成したのは「Contacts Record」だけ
リンク元のリソースに直接クエリを投げようとすると、「Schema ‘connect_datalake’ does not exist」と言われてエラーになりました。
リンク元のリソースはconnect_datalakeというDatabaseに属しているのですが、そこへのアクセス権がない、という感じですね。
使いたいリソースには忘れずリンクを作成するようにしましょう。
まとめ
Amazon ConnectのZero-ETLデータアクセスを試してみました。
複雑なETLパイプラインを自分で構築することなく、分析に使えるデータにアクセスすることができました。
あと気になるのはクエリの性能の最適化でしょうか。
KinesisやGlueでETLをするときはパーティショニングなどの工夫によってコストの抑制とクエリ性能の調整を行っていましたが、
今回作成したテーブルのフォーマットであるApache IcebergではS3のデータのコンパクションにより性能の調整ができるようです。
Optimizing Iceberg tables – AWS Lake Formation
この辺りは今後調査を行って、ETLを自分で構築するパターンとZero-ETLを使うパターンのどちらを取るかの判断材料にしていきたいところです。
- 中級figma教室 - 2024-12-24
- おすすめガジェット紹介!2024年12月編 - 2024-12-21
- Amazon ConnectでNGワードをリアルタイムに検知してSlackに通知する - 2024-12-16
- AWS Amplify AI KitでAIチャットアプリを爆速で作ってみる - 2024-12-14
- AWS LambdaをC#で実装する(ついでにラムダ式を書く) - 2024-12-09
【採用情報】一緒に働く仲間を募集しています







