こんにちは。久々の投稿となります。
以前Juliusを使った音声認識システムの作成という内容で記事を書いており、
その際後半は次回でと言いつつ、かなり間が空いてしまいました(笑)。
前回の記事にて途中まで(juliusインストールから単体での起動)しか記載していませんでしたので、今回はその後半として、実際に音声をサーバにアップし、その音声をjuliusにて認識、結果をブラウザ画面に表示させるまでを記載していきます。
また、サーバ処理はNode.JSで記述しております。
画面上から音声をアップし解析結果を表示させたい
やりたかったのは、ブラウザ画面から音声をアップロードし、それを解析した結果を画面上に表示させることでした。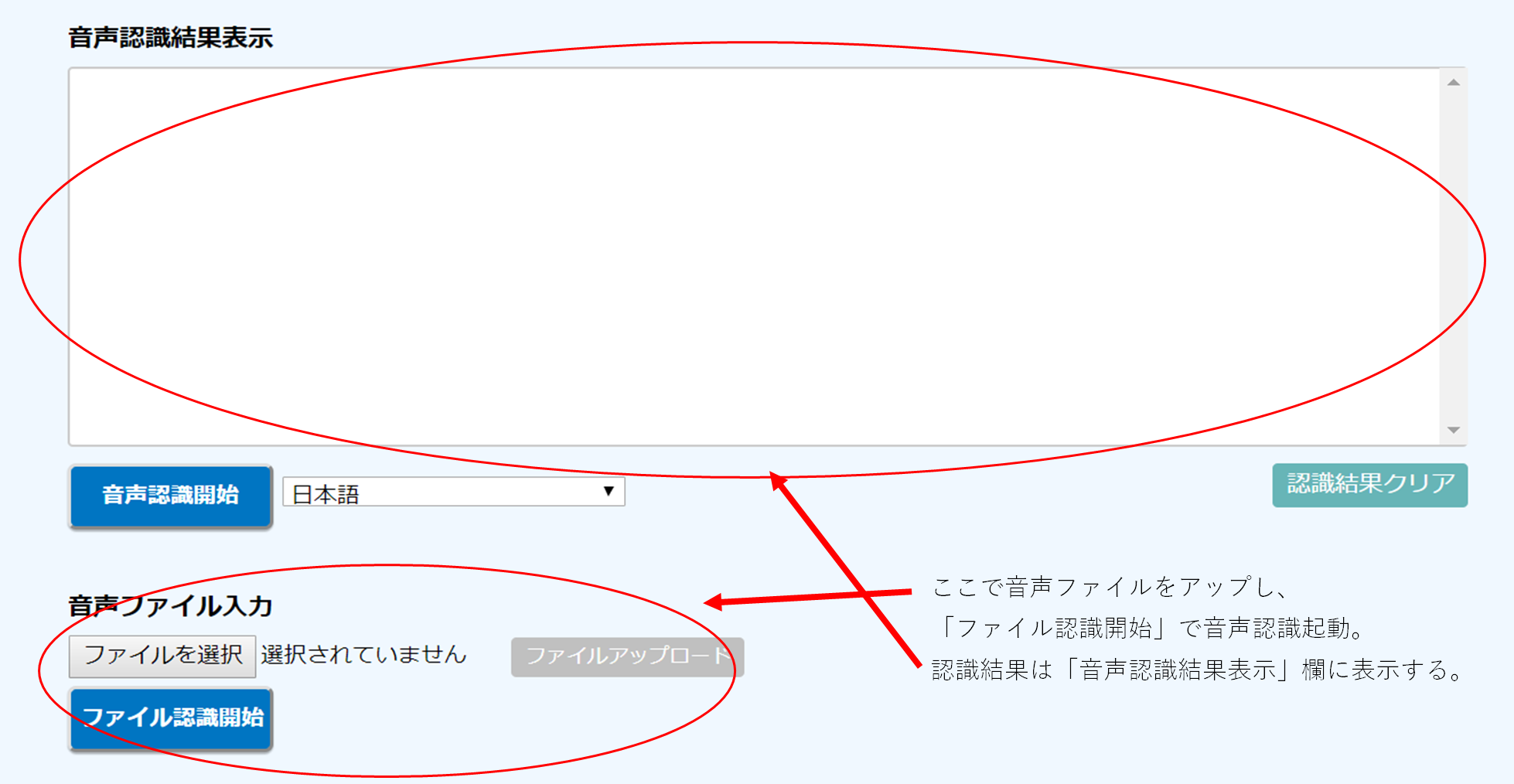
Juliusは起動時にオプションを指定することで、音声データの入力方法を指定することが可能です。
以下の方法から選択が可能となっています。
入力方法
- 音声波形入力(基本フォーマット)
- ファイル入力(-input rawfile)
- 録音デバイスからの直接入力(-input mic)
- ネットワーク・ソケット経由の入力(-input adinnet)
- 特徴量ファイル入力(-input htkparam,-input mfcfile)
今回はこのオプションにてファイル入力を指定し、出力した結果を取得しブラウザ画面上の結果エリアに表示させることにしました。
音声アップロード処理の実装
音声アップロードについては、インターフェースを作成し、ファイルアップロード処理を行った際にサーバ側にてリクエストを受け取った後、サーバ内の「/home/user/voicefile」のディレクトリ配下に格納されるようにしました。
以下ではサーバにてリクエストを受け取ってから格納までの処理を記述しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
if ('/upload' == url) { var upload = multer({dest: '/home/user/voicetemp/'}).single('upName'); upload(req, res, function(err) { if(err) { res.write('failed to write with '+ err); } else { fs.readFile(req.file.path, function (err, data) { fs.writeFile('/home/user/voicefile/voice3.wav', data, function (err) { if (err) { console.log(err); } else { fs.unlink('/home/user/voicetemp/' + req.file.filename, function (err) { if (err) { console.log(err); } }); } res.write("upload成功"); res.end(); }); }); } }); } |
ちなみに、音声は以下の形式でないとJuliusが認識してくれないので注意。
- .wavファイル:
Microsoft WAVE形式 WAVファイル(16bit, 無圧縮PCM, monoral のみ) - ヘッダ無しRAWファイル:データ形式は signed short (16bit),Big Endian, monoral
ここまでできたら/home/user/voicefile/voice3.wavを対象の音声ファイルとし、juliusを起動させます。
Juliusでの音声認識
クライアントにて「音声認識」ボタンを押下後、それを受け取ったサーバ側でJuliusを起動させ、アップロードした音声ファイルを対象に音声認識を開始します。
(他にもっといい方法がありそうな気もしますが、)今回は起動コマンドを直接実行する方法で行いました。
※Juliusにはmoduleモードというものがあり、最初はmoduleモードで起動させようとしたのですが、moduleモードの場合多重起動できず、複数の画面で起動させた場合にうまくいかなくなる為標準入力にて実行するやり方に変更しました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
socket.on('fileStart',function (data) { engine = data; console.log('Juliusファイル認識start'); juliusFileExe = spawn('julius', ['-C', '/home/user/dictation-kit-v4.4/main.jconf', '-C', '/home/user/dictation-kit-v4.4/am-gmm.jconf', '-demo', '-nostrip', '-input', 'rawfile', '-cutsilence', '-realtime']); // Julius起動コマンド juliusFileExe.stdout.setEncoding('utf8'); // 標準出力にて表示された結果を加工する juliusFileExe.stdout.on('data', function(data) { io.sockets.emit('fileResultinternal',''); var resultStart = data.indexOf('sentence1'); var resultdata; if(resultStart > 1){ resultdata = data.match(/sentence1.*。/); resultdata = resultdata.toString().replace(/sentence1:|\s/g,''); console.log(resultdata); io.sockets.emit('fileResultSend',resultdata); //結果をブラウザへ送る } } ); if (juliusFileExe !== null) { // 対象となるファイルを標準入力にて指定 juliusFileExe.stdin.write('/home/user/voicefile/voice3.wav'); juliusFileExe.stdin.end(); } }); |
Julius起動のコマンドのオプションについては以下の通りとなります。
-input rawfile 音声入力方法をファイルに指定
-cutsilence ファイル内の音声をいったんマイク入力と同じ基準で(長時間の無音ごとに)切り出し,その切り出しごとに処理を行う
-realtime マイク入力と同様に入力と認識を並列処理する
-nostrip 音声波形中の振幅 が “0” となるフレームを除去するが、うまく動かない場合このオプションを指定することで自動消去を 無効化することができる(らしい)
※これつけないと認識時にwarningがたくさん出力されたのでオプション指定してます
Julius起動後、対象となる音声ファイルを標準入力にて指定します。
そうすることで標準出力にて結果が表示されますが、以下のような形で結果が出力される為、結果を加工して実際の認識結果箇所のみに抽出する必要があります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
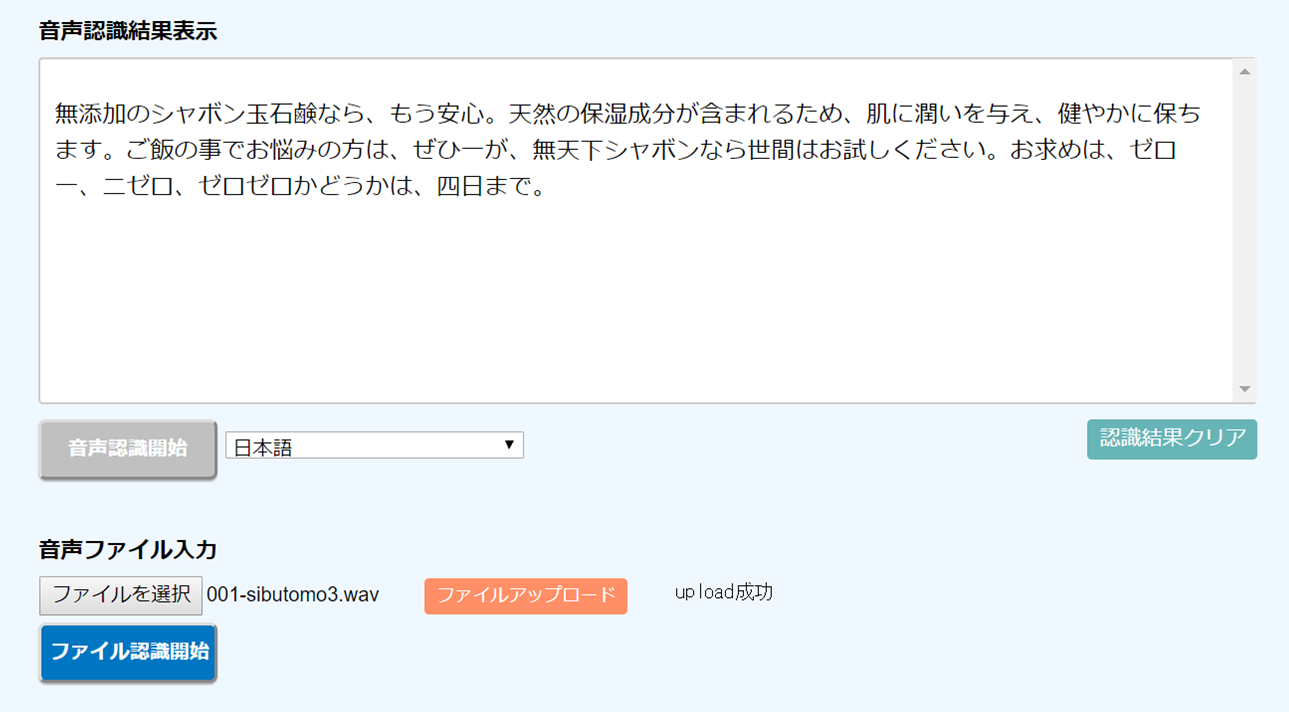
enter filename->/home/user/voicefile/voice3.wav Stat: adin_file: input speechfile: /home/user/voicefile/voice3.wav pass1_best: 無 添加 の サバンナ は 世間 が 、 もう 三 安心 。STAT: triggered: [14200..69000] 3.42s from 00:00:0.89 pass1_best: 無 添加 の サバンナ は 世間 が 、 もう 安心 。 sentence1: 無 添加 の シャボン 玉 石鹸 なら 、 もう 安心 。 pass1_best: 健全 な 本質 成分 が 含ま れる ため 、 肌 に も 言わ れ 、 健やか に 保ち ます 。STAT: triggered: [77200..171000] 5.86s from 00:00:4.82 pass1_best: 健全 な 本質 成分 が 含ま れる ため 、 肌 に も 言わ れ 、 健やか に 保ち ます 。 sentence1: 天然 の 保湿 成分 が 含ま れる ため 、 肌 に 潤い を 与え 、 健やか に 保ち ます 。 pass1_best: ご飯 の こと の 悩み の 方 は ぜひ 一 が 、 無 添加 シャボン 玉 石鹸 は 試し ください 。STAT: triggered: [179200..276000] 6.05s from 00:00:11.20 pass1_best: ご飯 の こと の 悩み の 方 は ぜひ 一 が 、 無 添加 シャボン 玉 石鹸 は 試し ください 。 sentence1: ご飯 の 事 で お 悩み の 方 は 、 ぜひ 一 が 、 無 天下 シャボン なら 世間 は お 試し ください 。 pass1_best: 大元 A は 、 ゼロ 一 二 で は ゼロ ゼロ と が 、 規範 が ね 。STAT: triggered: [285200..368000] 5.18s from 00:00:17.83 pass1_best: 大元 A は 、 ゼロ 一 二 で は ゼロ ゼロ と が 、 規範 が ね 。 sentence1: お 求め は 、 ゼロ 一、二 ゼロ 、 ゼロ ゼロ か どう か は 、 四 日 まで 。 STAT: no input frame |
pass1_bestは、中間認識結果で、最終的な結果としてはsentence1に表示されます。
なので、sentence1の結果のみ切り出してresultdataとしてクライアントに返却しています。
ちなみに相変わらずの認識率についてはご愛敬ということで(笑)
結果の表示
結果を画面上に表示します。
ここで一つ問題がありました。Julius起動時のオプションとして「-cutsilence」を指定している為、返却される結果はセンテンス毎に送られてきます。その為、どのタイミングで認識終了なのかがわかりませんでした。
そしてブラウザ上では認識実施中は「認識開始」ボタンをdisableにしており、完了後に解除するという仕様を想定していたので、この状態では解除するタイミングがわかりません。
それを解決する為に、結果受信時にタイマーを起動し、15秒経っても次の結果が送られてこなかった場合に認識完了とすることとしました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
//ファイル認識結果をサーバから受信 socketio.on('fileResultSend', function (data) { finalText = data; resultProcess(); endCount(); }); //認識中のタイマー var count = 0; function countUp() { count++; console.log(count); } //認識開始時に「認識開始」ボタンを「認識中」にしdisableにする socketio.on('fileResultinternal', function(){ if(count == 0){ endCount(); } else { count = 1; } btn3.value = '認識中'; document.getElementById("btn3").disabled = true; }); //前回の結果受信後15秒経っているか確認 function endCount () { if (count == 0){ var Timer = setInterval( function(){ countUp(); //15秒経ったら認識完了とし、認識開始ボタンを有効化する if (count > 15){ btn3.value = 'ファイル認識開始'; btn3.className = 'startbtn'; document.getElementById("btn3").disabled = false; socketio.emit("JuliusEnd"); clearInterval(Timer); count = 0; } },1000); } else { count = 1; } } |
また、以下の処理にてサーバから取得した認識結果を画面上のテキストボックスに表示させます。
ちなみに今回はブラウザ画面上にキーワードを10個まで入力可能にしており、認識結果にそのキーワードが含まれていた場合、ハイライトを付ける処理を含めておりました。
今回の記事の趣旨とは逸れる為ここでは詳細を省いておりますが、結果表示においてこの処理も行っている為、それも含めた処理を以下に記述しております。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
//認識結果処理 function resultProcess() { serchword(finalText); if (finalText) { markCompArea.innerHTML += markSetArea.innerHTML; markSetArea.innerHTML = ''; } interimText = ''; finalText = ''; } //キーワード有無確認(ブラウザから10個のキーワード入力が可能な為、入力分処理を繰り返す) function serchword(word) { if (word) { var sercharea = finalText; } else { var sercharea = interimText; } for (var i = 0; i < 10; i++) { var serchkey = document.getElementById("keywordinput" + [i]).value; if (serchkey) { sercharea = replacer(sercharea, serchkey, "mark1"); } else { } } markSetArea.innerHTML = sercharea; } //入力したキーワードに当てはまる箇所にハイライトタグを追加する function replacer(str, word, att) { var SearchString = '(' + word + ')'; var RegularExp = new RegExp(SearchString, "g"); var ReplaceString = '<span class="' + att + '">$1</span>'; var ResString = str.replace(RegularExp, ReplaceString); return ResString; } |
markCompAreaというテキストボックスが結果表示欄となる為、これで結果が画面上に表示されます。
Juliusで音声認識システムを作ってみて
Juliusを使って音声認識させるという記事は探せばいろいろあったのですが、自分がやりたい事に対してピンポイントでマッチするようなものはなかったので模索しながら実施しました。
とりあえずできるようになることを優先に進めていたので、一応こういう方法でもできますよという感じで参考にしてもらえればと思います。
juliusは初めて触ったのですが、自サーバ内に構築可能なので、外部に接続せずとも使えるというところはいいですね。
ちなみに今回認識精度についてはあまり気にしていなかったのですが、Juliusの場合は辞書の内容によってかなり認識精度変わってくるようなので、使用する辞書によっては精度がかなり上がってくるのではないかと思います。
- 中級figma教室 - 2024-12-24
- おすすめガジェット紹介!2024年12月編 - 2024-12-21
- Amazon ConnectでNGワードをリアルタイムに検知してSlackに通知する - 2024-12-16
- AWS Amplify AI KitでAIチャットアプリを爆速で作ってみる - 2024-12-14
- AWS LambdaをC#で実装する(ついでにラムダ式を書く) - 2024-12-09
【採用情報】一緒に働く仲間を募集しています







